JSP에는 기본적으로 두가지 방법의 페이지 안에 다른 컨텐츠를 추가하는 방법이 존재합니다. include지시자와 <jsp:include> 액션이 있는데요. 하지만 둘 모두 같은 웹 어플리케이션 또는 서블릿 컨텍스트 안에있는 페이지만을 불어들일 수 있습니다. core라이브러리에 있는 <c:import> 액션은 좀더 일반적이고 강력한 기능을 가진 <jsp:include>로 볼 수 있습니다. 사용 문법은 <c:url>과 매우 배슷하며 심지어 <c:param>도 그대로 사용할 수 있습니다.
<c:import>에는 var와 scope 두가지 필수적이지 않은 속성이 존재하는데요. var의 경우에는 불러들인 페이지를 곧바로 출력하지 않고 String형 변수로 담아두기 위해 사용됩니다. scope는 이 변수의 스코프를 지정할 수 있습니다. 기본적으로 page로 되어있습니다.
<c:catch>로 예외처리 하기
길게 설명할 필요가 없을것 같네요. <c:import>는 ftp에도 접속이 가능합니다. 다음에 보여드릴 코드의 경우 만약에 해당 위치에 파일이 존재하지 않거나 네트워크의 문제로 페이지를 불러올 수 없는 상황이라면 예외가 발생할 것입니다. 예외가 발생할 경우 var에 예외가 저장됩니다. <c:if>를 통해 예외가 발생했는지 확인하는 예제입니다
이 액션은 <jsp:forward> 액션과도 매우 흡사합니다. 하지만 이 기능의 경우에는 서버사이드에서 구현된 요청형태만을 포워딩 합니다. 이게 무슨 말이냐면 포워딩의 경우에는 사용자 입장에서 보면 페이지의 이동 없이 다른 페이지를 띄워줄 수 있지만 리다이렉트의 경우에는 브라우저에 의해 페이지의 이동이 일어나게 됩니다. 하지만 <c:redirect>액션이 좀 더 유연합니다. <jsp:forward>의 경우에는 현재 같은 서블릿 컨텍스트 내의 다른 페이지로만 이동 할 수 있기 때문입니다.
JavaScript는 단순한 언어로 여겨져 왔습니다. 그래서 여러 개발자분들이 JavaScript를 배우기도 쉽고 간단히 쓸 수 있다는 편견을 가지고있습니다. 하지만, 최근 JavaScript의 관심이 늘어나면서 JavaScript는 더이상 '쉬운 언어'가 아닌 깊은 이해를 필요로 하는 언어라는 인식이 생기고있습니다. 저는 JavaScript에 대한 깊은 이해를 하기 위해서는 클로저(Closure)에 대해 알아야 되며 이를 알기 위해서는 Scope 개념의이해가 필요하다고 생각됩니다.
JavaScript 프로그래밍에서 유효범위를 잘 알아야 하는 이유가 무엇일까요? 제 생각은 다음과 같습니다.
유효범위란 JavaScript에서뿐만 아니라 모든 프로그래밍 언어 코드의 가장 기본적인 개념의 하나로 반드시 알아야 합니다. 유효범위의 개념을 모르면 관련된 다른 개념 역시 혼란스러울 수 있습니다.
JavaScript의 유효범위에는 다른 언어의 유효범위와는 다릅니다. 다른 프로그래밍 언어에 익숙한 개발자들은 JavaScript만의 유효범위를 이해해야 합니다.
JavaScript의 유효범위 개념은 간단하게 생각한다면 너무나 쉬운 내용이면서도 쉽게 이해하지 못할 함정에 자주 빠지게 합니다. 돌다리도 두들겨보고 건너라는 말이 있듯이 기본 개념부터 튼튼히 하고 넘어가야 합니다.
1. 유효범위(Scope)
Scope를 직역하면 영역, 범위라는 뜻입니다. 하지만 프로그램 언어에서의 유효범위는 어느 범위까지 참조하는지. 즉, 변수와 매개변수(parameter)의 접근성과 생존기간을 뜻합니다. 따라서 유효범위 개념을 잘 알고 있다면 변수와 매개변수의 접근성과 생존기간을 제어할 수 있습니다. 유효범위의 종류는 크게 두 가지가 있습니다. 하나는 전역 유효범위(Global Scope), 또 하나는 지역 유효범위(Local Scope)입니다. 전역 유효범위는 스크립트 전체에서 참조되는 것을 의미하는데, 말 그대로 스크립트 내 어느 곳에서든 참조됩니다. 지역 유효범위는 정의된 함 수 안에서만 참조되는 것을 의미하며, 함수 밖에서는 참조하지 못합니다.
[그림 1] 유효범위 종류
위 그림은 유효범위의 종류에 대해 좀 더 설명하기 위해 첨부했습니다. 위 그림에서 전역변수(전역 유효범위를 가진 변수)는 globalscope이고 지역변수(지역 유효범위를 가진 변수)는 ascopeparam, localscopea, localscopeb, localscopec입니다. 각각의 지역 변수의 유효범위는 acopeparam, localscopea가 함수(Function) A의 중괄호 안의 영역, localscopeb가 함수 B의 중괄호 안의 영역, localscope_c가 함수 C의 중괄호 안의 영역입니다.
1.1 JavaScript 유효범위의 특징
앞서 JavaScript의 유효범위를 알아야 하는 이유에서 언급했듯 JavaScript의 유효범위는 다른 프로그래밍언어와 다른 개념을 갖습니다. JavaScript 유효범위만의 특징을 크게 분류하여 나열하면 다음과 같습니다.
함수 단위의 유효범위
변수명 중복 허용
var 키워드의 생략
렉시컬 특성
위와 같은 특징들을 지금부터 하나씩 살펴보겠습니다.
function scopeTest() {
var a = 0;
if (true) {
var b = 0;
for (var c = 0; c < 5; c++) {
console.log("c=" + c);
}
console.log("c=" + c);
}
console.log("b=" + b);
}
scopeTest();
//실행결과
/*
c = 0
c = 1
c = 2
c = 3
c = 4
c = 5
b = 0
*/
[예제 1] 유효범위 설정단위
위의 코드는 JavaScript의 유효범위 단위가 블록 단위가 아닌 함수 단위로 정의된다는 것을 설명하기 위한 예제 코드입니다. 다른 프로그래밍 언어들은 유효범위의 단위가 블록 단위이기 때문에 위의 코드와 같은 if문, for문 등 구문들이 사용되었을 때 중괄호 밖의 범위에서는 그 안의 변수를 사용할 수 없습니다. 하지만 JavaScript의 유효범위는 함수 단위이기 때문에 예제코드의 변수 a,b,c모두 같은 유효범위를 갖습니다. 그 결과, 실행화면을 보면 알 수 있듯이 구문 밖에서 그 변수를 참조합니다.
var scope = 10;
function scopeExam(){
var scope = 20;
console.log("scope = " +scope);
}
scopeExam();
//실행결과
/*
scope =20
*/
[예제 2] 변수 명 중복
JavaScript는 다른 프로그래밍 언어와는 달리 변수명이 중복되어도 에러가 나지 않습니다. 단, 같은 변수명이 여러 개 있는 변수를 참조할 때 가장 가까운 범위의 변수를 참조합니다. 위의 코드 실행화면을 보면 함수 내에서 scope를 호출했을 때 전역 변수 scope를 참조하는 것이 아니라 같은 함수 내에 있는 지역변수 scope를 참조합니다.
다른 프로그래밍 언어의 경우 변수를 선언할 때 int나 char와 같은 변수 형을 썼지만, JavaScript는 var 키워드를 사용합니다. 또, 다른 프로그래밍 언어의 경우 변수를 선언할 때 변수형을 쓰지 않을 경우 에러가 나지만 JavaScript는 var 키워드가 생략이 가능합니다. 단, var 키워드를 빼먹고 변수를 선언할 경우 전역 변수로 선언됩니다. 위 코드의 실행 결과를 보면 scope라는 변수가 함수 scopeExam 안에서 변수 선언이 이루어졌지만, var 키워드가 생략된 상태로 선언되어 함수 scopeExam2에서 호출을 했을 때도 참조합니다.
function f1(){
var a= 10;
f2();
}
function f2(){
return console.log("호출 실행");
}
f1();
//실행결과
/*
호출실행
*/
function f1(){
var a= 10;
f2();
}
function f2(){
return a;
}
f1();
//실행결과
/*
Uncaught Reference Error
: a is not defined
*/
[예제 4] 렉시컬 특성
렉시컬 특성이란 함수 실행 시 유효범위를 함수 실행 환경이 아닌 함수 정의 환경으로 참조하는 특성입니다. 위의 좌측코드를 봤을 때 함수 f1에서 함수 f2를 호출하면 실행이 됩니다. 함수 f1,f2 모두 전역에서 생성된 함수여서 서로를 참조할 수 있죠. 하지만 우측코드처럼 함수 f1안에서 함수 f2를 호출했다고 해서 f2가 f1안에 들어온 것처럼 f1의 내부 변수 a를 참조할 수 없습니다. 렉시컬 특성으로 인해서 함수 f2가 실행될 때가 아닌 정의 될 때의 환경을 보기 때문에 참조하는 a라는 변수를 찾을 수 없습니다. 그래서 실행결과는 위와 같이 나옵니다. 또 다른 JavaScript의 특징 중에 하나로 호이스팅이라는 개념이 있습니다. 호이스팅에 대해 살펴 보겠습니다.
1.2 호이스팅(Hoisting)
호이스팅이란 무엇일까요? Hoisting이라는 단어를 직역하면 끌어올리기, 들어 올려 나르기라는 뜻입니다. JavaScript에서 호이스팅도 비슷한 의미를 갖고 있습니다. 간단하게 말해서 JavaScript에서의 호이스팅의 의미는 변수 선언문을 끌어올린다는 뜻으로 이해하면 됩니다. 좀 더 이해를 돕기위해 아래의 코드를 준비했습니다.
function hoistingExam(){
console.log("value="+value);
var value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
function hoistingExam(){
var value;
console.log("value="+value);
value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
[예제 5] 호이스팅
위의 코드는 호이스팅을 설명하기 위한 간단한 예제입니다. 좌측 코드를 보시게 되면 함수 hoistingExam안에서 변수 value의 호출이 두 번 일어납니다. 한 번은 변수 선언문 전에 또 한 번은 변수 선언 후에 호출이 되는데, 다른 프로그래밍 언어의 경우에는 선언문 전에 호출됐을 때 에러가 납니다. 하지만 JavaScript의 경우 호이스팅이 됨으로써 오른쪽 코드와 같은 구동이 이루어집니다. 즉, 변수 선언문이 유효범위 안의 제일 상단부로 끌어올려 지게 되고, 선언문이 있던 자리에서 초기화가 이루어지는 결과를 갖는 것입니다. 그 실행결과 첫 번째 호출에서는 초기화가 되지 않은 undefined가, 두 번째 호출에서는 초기화된 값이 나옵니다.
var value=30;
function hoistingExam(){
console.log("value="+value);
var value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
[예제 6] 호이스팅 2
그렇다면 위와 같은 코드에서는 어떤 결과가 나올까요? 다른 프로그래밍 언어에 익숙한 개발자 분들은 변수 value의 첫 호출에서 전역변수가 참조된다고 생각하실 수 있습니다. 하지만 JavaScript의 호이스팅으로 인해서 선언 부가 함수 hoistingExam의 최 상단에서 끌어올려 짐으로써 전역변수가 아닌 지역변수를 참조합니다.
함수의 호이스팅을 이해할 때는 한 가지만 기억하시면 될 것 같습니다. 바로, 여러 가지의 함수 정의 방법 중 ‘함수 선언문 방식만 호이스팅이 가능하다.’라는 점입니다.
// 함수 선언문
hoistingExam();
function hoistingExam(){
var hoisting_val =10;
console.log("hoisting_val ="+hoisting_val);
}
//실행결과
/*
hoisting_val =10
*/
//함수 표현식
hoistingExam2();
var hoistingExam2 = function(){
var hoisting_val =10;
console.log("hoisting_val ="+hoisting_val);
}
//실행결과
/*
hoistingExam2 of object is not a function
*/
//Function 생성자
hoistingExam3();
var hoistingExam3 = new Function("","return console.log('Ya-ho!!');");
//실행결과
/*
hoistingExam3 of object is not a function
*/
[예제 7] 함수 호이스팅
앞서 말하였듯 위의 코드와 실행결과를 보시면 함수 선언문 방식만 호이스팅이 제대로 이루어집니다. 이 결과를 보고 왜 함수 선언문 방식만 호이스팅이 되고 함수 표현 식과 Function생성자를 통해 함수를 정의하는 방법은 호이스팅이 되지 않는지 궁금해하시는 분들도 계실 것 같은데요. 그 이유는 함수 표현 식과 Function생성자를 통한 함수 정의 방법은 변수에 함수를 초기화시키기 때문에(이를 함수변수라고도 합니다) 선언문이 호이스팅이 되어 상단으로 올려진다 하더라도 함수가 아닌 변수로써 인지되기 때문입니다. 위의 코드에서 함수실행 구문이 아닌 변수를 호출하게 되면 변수의 호이스팅과 같은 undefined란 결과가 나옵니다.
1.3 실행 문맥(Execution context)
실행 문맥은 간단하게 말해서 실행 정보입니다. 실행에 필요한 여러 가지 정보들을 담고 있는데 정보란 대부분 함수를 뜻합니다. JavaScript는 일종의 콜 스택(Call Stack)을 갖고 있는데, 이 곳에 실행 문맥이 쌓입니다. 콜 스택의 제일 위에 위치하는 실행 문맥이 현재 실행되고 있는 실행 문맥이 되는 것이죠.
console.log("전역 컨텍스트 입니다");
function Func1(){
console.log("첫 번째 함수입니다.");
};
function Func2(){
Func1();
console.log("두 번째 함수입니다.");
};
Func2();
//실행결과
/*
전역 컨텍스트 입니다
첫 번째 함수 입니다.
두 번째 함수 입니다
*/
[그림 2] 코드실행에 따른 실행문맥 스택
스크립트가 실행이 되면 콜 스택에 전역 컨텍스트가 쌓입니다. 위의 코드에서 함수 Func2의 실행 문구가 나와 함수가 실행이 되면 그 위에 Func2의 실행 컨텍스트가 쌓입니다. Func2가 실행되는 도중 함수 Func1이 실행이 되면서 콜 스택에는 Func2 실행 컨텍스트위에 Func1의 실행컨텍스트가 쌓이죠. 그렇게 Func1이 종료가되고 Func2가 종료가 되면서 차례로 컨텍스트들이 스택에서 빠져나오게됩니다. 마지막으로 스크립트가 종료가 되면 전역 컨텍스트가 빠져나오게 되는 구조입니다.
그렇다면 실행 문맥은 어떤 구조로 이루어져있고 어떤 과정을 통해 생성이 될까요? 지금부터 알아보겠습니다.
1.4 실행 문맥 생성
실행 문맥은 크게 3가지로 이루어져 있습니다.
활성화 객체: 실행에 필요한 여러 가지 정보들을 담을 객체입니다. 여러 가지 정보란 arguments객체와 변수등을 말합니다.
유효범위 정보: 현재 실행 문맥의 유효 범위를 나타냅니다.
this 객체: 현재 실행 문맥을 포함하는 객체 입니다.
[그림 3] 실행문맥 생성
위의 코드를 실행하게 되면 함수abcFunction의 실행 문구에서 위와 같은 실행 문맥이 생깁니다. 실행문맥 생성 순서는 다음과 같습니다.
활성화 객체 생성
arguments객체 생성
유효범위 정보 생성
변수 생성
this객체 바인딩
실행
arguments객체는 함수가 실행될 때 들어오는 매개변수들을 모아놓은 유사 배열 객체입니다. 위의 그림에서 Scope Chain이 유효범위 정보를 담는 일종의 리스트이며 0번지는 전역 변수 객체를 참조합니다. Scope Chain에 대해서는 뒤에 다시 한 번 설명하겠습니다. 변수들은 위의 코드의 지역변수와 매개변수 a,b,c 입니다. 매개변수 a와 b는 실행 문맥 생성단계에서 초기화 값이 들어가지만, c의 경우 생성 후 실행 단계에서 초기화가 되기 때문에 undefined란 값을 가지고 생성됩니다.
2. 유효범위 체인(Scope Chain)
유효범위 체인을 간단하게 설명하면 함수가 중첩함수일 때 상위함수의 유효범위까지 흡수하는 것을 말합니다. 즉, 하위함수가 실행되는 동안 참조하는 상위 함수의 변수 또는 함수의 메모리를 참조하는 것입니다. 앞서 실행 문맥 생성에 대해 설명했듯이 함수가 실행될 때 유효범위를 생성하고 해당 함수를 호출한 부모 함수가 가진 활성화 객체가 리스트에 추가됩니다.
[그림 4] 유효범위 체인 관계형성
쉽게 말해서 위와 같은 코드를 실행할 때 전역 변수 객체, 상 하위 객체 간에 부모/자식 관계가 형성된다고 생각하시면 쉽게 이해 할 수 있습니다. 위의 코드를 실행 문맥 개념으로 좀 더 자세히 보면 다음과 같은 구조를 가집니다.
[그림 5] 유효범위 체인
(앞으로 활성화 객체는 변수 객체와 같기 때문에 변수 객체라고 부르겠습니다) 함수 outerFunction이 실행 되면 outerFunction의 실행 문맥이 생성이 되고 그 과정은 앞선 실행 문맥 생성과정과 동일합니다. outerFunction이 실행이 되면서 내부 함수 innerFunction이 실행되면 innerFunction실행 문맥이 생성이 되는데 유효범위 정보가 생성이 되면서 outerFuction과는 조금 차이가있는 유효범위 체인 리스트가 생깁니다. innerFunction 실행문맥의 유효범위 체인 리스트는 1번지에 상위 함수인 outerFunction의 변수 객체를 참조합니다. 만약 innerFunction내부에 새로운 내부 함수가 생기게 되면 그 내부함수의 유효범위 체인의 1번지는 outerFunction의 변수 객체를, 2번지는 innerFunction의 변수 객체를 참조합니다.
이어서 이 유효범위 체인을 이용한 클로저에 대해 알아 봅니다.
3. 클로저(Closure)
클로저는 JavaScript의 유효범위 체인을 이용하여 이미 생명 주기가 끝난 외부 함수의 변수를 참조하는 방법입니다. 외부 함수가 종료되더라도 내부함수가 실행되는 상태면 내부함수에서 참조하는 외부함수는 닫히지 못하고 내부함수에 의해서 닫히게 되어 클로저라 불리 웁니다. 따라서 클로저란 외부에서 내부 변수에 접근할 수 있도록 하는 함수입니다.
내부 변수는 하나의 클로저에만 종속될 필요는 없으며 외부 함수가 실행 될 때마다 새로운 유효범위 체인과 새로운 내부 변수를 생성합니다. 또, 클로저가 참조하는 내부 변수는 실제 내부 변수의 복사본이 아닌 그 내부 변수를 직접 참조합니다.
function outerFunc(){
var a= 0;
return {
innerFunc1 : function(){
a+=1;
console.log("a :"+a);
},
innerFunc2 : function(){
a+=2;
console.log("a :"+a);
}
};
}
var out = outerFunc();
out.innerFunc1();
out.innerFunc2();
out.innerFunc2();
out.innerFunc1();
//실행결과
/*
a = 1
a = 3
a = 5
a = 6
*/
function outerFunc(){
var a= 0;
return {
innerFunc1 : function(){
a+=1;
console.log("a :"+a);
},
innerFunc2 : function(){
a+=2;
console.log("a :"+a);
}
};
}
var out = outerFunc();
var out2 = outerFunc();
out.innerFunc1();
out.innerFunc2();
out2.innerFunc1();
out2.innerFunc2();
//실행결과
/*
a = 1
a = 3
a = 1
a = 3
*/
[예제 8] 클로저의 상호작용, 서로 다른 객체
위의 코드는 클로저의 예제 코드이며 그 중 좌측 코드는 서로 다른 클로저가 같은 내부 변수를 참조하고 있다는 것을 보여주고 있습니다. 서로 다른 클로저 innerFunc1과 innerFunc2가 내부 변수 a를 참조하고 a의 값을 바꿔주고 있습니다. 실행 결과를 보면 내부 변수 a의 메모리를 같이 공유한다는 것을 알 수 있습니다.
우측 코드는 같은 함수를 쓰지만 서로 다른 객체로 내부 변수를 참조하는 모습입니다. 외부 함수가 여러 번 실행되면서 서로 다른 객체가 생성되고 객체가 생성될 때 마다 서로 다른 내부 변수가 생성되어 보기엔 같은 내부 변수 a로 보이지만 서로 다른 내부 변수를 참조합니다.
3.1 클로저의 사용이유
클로저를 사용하게 되면 전역변수의 오,남용이 없는 깔끔한 스크립트를 작성 할 수 있습니다. 같은 변수를 사용하고자 할 때 전역 변수가 아닌 클로저를 통해 같은 내부 변수를 참조하게 되면 전역변수의 오남용을 줄일 수 있습니다. 또한, 클로저는 JavaScript에 적합한 방식의 스크립트를 구성하고 다양한 JavaScript의 디자인 패턴을 적용할 수 있습니다. 그의 대표적인 예로 모듈 패턴을 말 할 수 있는데 모듈 패턴의 자세한 내용은 [Javascript : 함수(function) 다시 보기]을 참고 하시면 될 것 같습니다. 마지막으로 함수 내부의 함수를 이용해 함수 내부변수 또는 함수에 접근 함으로써 JavaScript에 없는 class의 역할을 대신해 비공개 속성/함수, 공개 속성/함수에 접근을 함으로 class를 구현하는 근거 입니다.
3.2 클로저 사용시 주의할 점
클로저를 사용할 때 주의해야 할 점이 여럿 있습니다. 제가 알려드리고 싶은 주의 점은 다음과 같습니다.
for 문 클로저는 상위 함수의 변수를 참조할 때 자신의 생성될 때가 아닌 내부 변수의 최종 값을 참조합니다.
<body>
<script>
window.onload = function(){
var list = document.getElementsByTagName("button");
for(var i =0, length = list.length; i<length; i++){
list[i].onclick=function(){
console.log(this.innerHTML+"은"+(i+1)+"번째 버튼입니다");
}
}
}
</script>
<button>1번째 버튼</button>
<button>2번째 버튼</button>
<button>3번째 버튼</button>
</body>
//실행결과
/*
1번째 버튼은 4번째 버튼입니다
2번째 버튼은 4번째 버튼입니다
3번째 버튼은 4번째 버튼입니다
*/
[예제 9] for문안의 클로저
위의 코드는 각각의 버튼에 이벤트를 걸어 클릭된 버튼이 몇 번째 버튼인지를 알기 위한 예제 입니다. 하지만, 실행 결과 값은 바라던 결과가 나오지 않습니다. 위의 클로저인 클릭 이벤트가 참조 하는 변수 i의 값이 버튼이 클릭될 때의 값이 아닌 for 구문을 다 돌고 난후 i의 값 4를 참조하기 때문에 모두 4라는 결과가 나옵니다.
<body>
<script>
window.onload = function(){
var list = document.getElementsByTagName("button");
var gate = function(i){
list[i].onclick=function(){
console.log(this.innerHTML+"은"+(i+1)+"번째 버튼입니다");
}
}
for(var i =0, length = list.length; i<length; i++){
gate(i);
}
}
</script>
<button>1번째 버튼</button>
<button>2번째 버튼</button>
<button>3번째 버튼</button>
</body>
//실행결과
/*
1번째 버튼은 1번째 버튼입니다
2번째 버튼은 2번째 버튼입니다
3번째 버튼은 3번째 버튼입니다
*/
[예제 10] 예제9 해결법 : 중첩클로저
위의 예제 코드를 통해 중첩 된 클로저를 사용하는 것 만으로 위와 같은 문제를 피하여 원하는 값이 나옵니다.
성능문제 클로저가 필요하지 않는 부분에서 클로저를 사용하는 것은 처리 속도와 메모리 면에서 좋은 방법이 아닙니다.
function MyObject(inputname) {
this.name = inputname;
this.getName = function() {
return this.name;
};
this.setName = function(rename) {
this.name = rename;
};
}
var obj= new MyObject("서");
console.log(obj.getName());
//실행결과
/*
서
*/
[예제 11] 클로저의 오남용
위의 코드와 같은 함수 내부의 클로저 구현은 함수의 객체가 생성될 때마다 클로저가 생성되는 결과를 가져옵니다. 같은 구동을하는 클로저가 객체마다 생성이 된다면 쓸데없이 메모리를 쓸데없이 차지하게 되는데, 이를 클로저의 오남용이라고 합니다. 클로저의 오남용은 성능 문제 면에서 안 좋은 결과를 가져옵니다.
function MyObject(inputname) {
this.name = inputname;
}
MyObject.prototype.getName = function() {
return this.name;
};
MyObject.prototype.setName = function(rename) {
this.name = rename;
};
var obj= new MyObject("서");
console.log(obj.getName());
//실행결과
/*
서
*/
[예제 12] prototype객체를 이용한 클로저 생성
클로저를 위의 코드와 같이 prototype객체에 생성하게 되면 객체가 아무리 생성되어도 클로저를 한 번만 생성하고 여러 객체에서 쓸 수 있게 되어 메모리의 낭비를 줄입니다.
function f1(){
function f2(){
console.log(arguments[0]);
}
return f2;
}
var exam = f1(1);
exam();
//실행결과
/*
undefined
*/
function f1(){
var a= arguments[0];
function f2(){
console.log(a);
}
return f2;
}
var exam = f1(1);
exam();
//실행결과
/*
1
*/
[예제 13] arguments객체 참조
위의 좌측코드같이 클로저를 통해 arguments객체를 참조하게 되면 undefined라는 실행결과가 나옵니다. 즉, arguments객체는 참조가 불가능하며 굳이 참조하고 싶다면 오른쪽 코드와 같이 새로운 내부 변수에 arguments객체의 값을 넣고 그 변수를 참조 하거나 매개변수를 만들어 매개 변수를 참조하여야 합니다.
Function 생성자
var a= 20;
function function1(){
var a= 10;
var function2 = new Function("","return a;");
return function2;
}
var exam = function1();
exam();
//실행결과
/*
20
*/
[예제 14] Function생성자로 선언된 클로저
위의 코드와 같이 클로저가 Function생성자로 생성된 경우 전역에서 생성된 것으로 인지합니다. 클로저 function2를 통하여 내부 변수 a를 참조하려고 했지만 원했던 결과와 달리 전역 변수 a가 참조 됩니다.
순환참조
function outerFunc(){
var outer_val = {};
function innerFunc(){
console.log(outer_val);
}
outer_val.values = innerFunc;
return innerFunc;
}
[예제 15] 인위적 순환참조
위의 코드는 의도적으로 클로저의 순환참조를 만든 예제 코드입니다. 내부 객체 outerval의 속성 값 values 에 내부 함수 innerFunc를 참조하게 만들고 내부 함수 innerFunc는 내부 객체 outerval을 호출 하고 있습니다. 위와 같은 순환 참조는 서로를 참조 하면서 영원히 끝나지 않는 호출로 인하여 메모리 누수를 야기합니다.
function outerFunc(){
var outer_val = {};
function innerFunc(){
console.log("Hello");
}
outer_val.values = innerFunc;
return innerFunc;
}
[예제 16] 의도치 않은 순환참조
그렇다면 위 코드같이 서로를 참조를 하지 않게 되면 순환참조가 끊어질까요? 아닙니다. JavaScript의 클로저는 특별한 문법을 쓰지 않고도 암묵적으로 생기는 특성을 가지고 있습니다. 이는 클로저를 쉽게 만들도록 해주지만 클로저가 사용되는 곳을 사용자가 식별하기 어렵게 만들기도 합니다. 그렇게 되면 내부 함수의 innerFunc는 암묵적으로 상위 함수의 내부 객체인 outer_val을 참조하게 되고 이로인해 의도치 않게 순환참조가 만들어집니다. 이런 의도치 않은 순환참조는 메모리 누수를 야기합니다.
이 같은 의도치 않은 순환참조는 객체가 제거될 때 명시적으로 null값으로 초기화 해 주거나 try-catch-finally구문으로 해결합니다. 또는 더 글라스 크락포드가 제시한 purge함수를 쓰게 되면 순환참조를 해결할 수 있습니다. 아래는 purge함수 입니다.
function purge(d) {
var a = d.attributes, i, l, n;
if (a) {
for (i = a.length - 1; i >= 0; i -= 1) {
n = a[i].name;
if (typeof d[n] === 'function') {
d[n] = null;
}
}
}
a = d.childNodes;
if (a) {
l = a.length;
for (i = 0; i < l; i += 1) {
purge(d.childNodes[i]);
}
}
}
[더글라스 크락포드의 purge함수]
3.3 캡슐화
캡슐화란 간단하게 말하면 객체의 자료화 행위를 하나로 묶고, 실제 구현 내용을 외부에 감추는 겁니다. 즉, 외부에서 볼 때는 실제 하는 것이 아닌 추상화 되어 보이게 하는 것으로 정보은닉에 쓰입니다. JavaScript는 이와 같은 캡슐화를 클로저를 사용하여 구현합니다.
function Gugudan(dan){
this.maxDan=3;
this.calculate = function(){
for(var i =1; i<=this.maxDan; i++){
console.log(dan+"*"+i+"="+dan*i);
}
}
this.setMaxDan = function(reset){
this.maxDan = reset;
}
}
var dan5 = new Gugudan(5);
dan5.calculate();
dan5.maxDan=2;
dan5.calculate();
//실행결과
/*
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
*/
[예제 17] 캡슐화 전
위의 코드는 JavaScript 캡슐화 하기 전의 코드입니다. 내부 변수를 this객체로 바인딩 하여 선언하게 되면 내부 변수 maxDan에 대하여 외부에서 직접 접근이 가능합니다. 이런식의 소스코드 구현은 사용자가 임의로 바꿔선 안될 값들이 외부에 공개가 되면서 보안문제에 안좋은 결과를 가져옵니다.
function Gugudan(dan){
var maxDan=3;
this.calculate = function(){
for(var i =1; i<=maxDan; i++){
console.log(dan+"*"+i+"="+dan*i);
}
}
this.setMaxDan = function(reset){
maxDan = reset;
}
}
var dan5 = new Gugudan(5);
dan5.calculate();
dan5.maxDan=2;
dan5.calculate();
dan5.setMaxDan(2)
dan5.calculate();
//실행결과
/*
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
*/
[예제 18] 캡슐화 후
하지만 위의 코드와 같이 var키워드를 통하여 내부 변수를 선언하게 되면 내부 변수 maxDan이 외부에서 직접 접근이 되지 않고 오직 클로저를 통해서만 접근이 가능합니다. 즉, 사용자가 임의로 값을 바꿀수 없고 개발자가 만들어놓은 길(클로저)을 통해서만 값을 바꿔 줄수 있습니다. 아쉬운 점은 캡슐화를 하게되면 클로저를 prototype 맴버로 등록하지 못해 공용 메소드로 사용할 수 있는 이점은 사라집니다. 하지만, 별도의 부모 객체를 정의해서 공용 메소드나 상수 들을 위치시키고 이를 상속받는 방식으로 보완할 수 있습니다.
맺음말
다른 프로그래밍 언어와는 조금 다른, 그리고 반드시 알고 지나가야 하는 JavaScript의 유효범위의 개념에대해서 공부하고 정리해보았습니다. 많이 부족한 글이지만 저와같은 초보개발자 분들, 또는 JavaScript를 공부하고 계신 분들에게 조금이나마 도움이 되었으면 하는 바램입니다. 이렇게 글을쓰고 정리하면서 저 또한 많은 공부가 되었던 것 같습니다. 글을 읽으시다가 혹여, 틀리거나 조금 더 정확한 표현이 가능한 부분들이 있다고 생각되시면 바로 저에게 채찍질을 해주셨으면 좋겠습니다. 한 번 틀렸던 부분을 다시알게되면 저에게도 많은 도움이 될 것 같습니다. 읽어 주셔서 감사합니다.
Button이 Renderable들의 render 코드를 호출하는 대신에, 이벤트 주도(감시자 패턴, 출판-구독 패턴..) 방식으로 Renderable이라는 제약사항을 없앨 수도 있습니다.
새로운 요구사항
Balls, Text을 Renderable에서 탈피시키며 의존성을 완전히 없애기
classText{constructor(){this.view = document.createElement('div');
document.body.append(this.view);this.number =0;this.count();}count(){this.view.textContent = `[${this.number++}]`;}}classBalls{constructor(){this.view = document.createElement('div');
document.body.append(this.view);}generate(){this.view.innerHTML ='';let number = Math.floor(Math.random()*10);for(let i=0; i<number; i++){let ball = document.createElement('div');
ball.style.background ='orange';
ball.style.width = ball.style.height ='1em';
ball.style.borderRadius ='50%';
ball.style.display ='inline-block';this.view.appendChild(ball);}}}classButton{constructor(text){this.view = document.createElement('button');this.view.textContent = text;
document.body.append(this.view);this.clickHandlers =[];this.view.onclick =()=>{this.clicked++;this.clickHandlers.forEach(handler =>handler(this.clicked));}}addClickHandler(handler){this.clickHandlers.push(handler);}}let balls =newBalls();let text =newText();// increment button
let button =newButton("INCREMENT");
button.addClickHandler(()=>{
text.count();});// button for both
let button2 =newButton("CLICK ME");
button2.addClickHandler(()=>{
balls.generate();
text.count();});
이제 Button은 인스턴스별로 원하는 hook(callback, handler, listener, observer 등..)을 등록하여 입맛대로 쓸 수 있습니다.
* 아시는 것처럼 DOM에는 당연히 native로 각종 이벤트 핸들러를 부착할 수 있습니다, JS를 예시로 들다보니 같은 작업을 중복한 꼴이 되었습니다만, 지금 예시로 든 GUI 뿐 아니라 그 어떤 코드에서도 의존성에서 탈피하기 위해서 같은 원리를 적용 할 수 있음을 말하고자 합니다.
맺음말.
의존성에서 벗어나야 좋은 코드라는데, 위 처럼 의존성이 하나도 없는게 최고군요!
의존성이 없으면 그만큼 확장성이 있지만, 원하는 대로 그 쓰임새를 강제 할수가 없습니다.
예를 들어서 현금,부동산 등을 등록 할 수 있는 회계사가 있다고 해봅시다. 회계사는 현금, 부동산과 현금으로평가할수있는 인터페이스로 느슨하게 연결되어 있습니다.
interface 현금으로평가할수있는 {
금액 현금으로평가();}
이를 통해서 회계사는 현금이나 부동산 등을 현금으로 평가하여 다룰 수 있습니다. 또한 비트코인이라는 새로운 객체에도 현금으로평가할수있는이라는 명시적인 인터페이스만 구현해준다면 쉽게 회계사와 연결 할 수 있습니다.
이렇게 적절한 의존성을 통해서 쓰임새의 방향을 어느 정도 강제하고, 확장의 가이드가 될 수 있습니다.
---
디자인 패턴을 공부해도 막상 실제 코드엔 적용하기가 쉽지 않습니다. 저는 코드의 구조에 그 합당한 이유가 있어야 한다는 생각을 합니다. 아무런 필요도 준비도 없이, 디자인패턴들을 되새김질하며 마치 공식처럼 적용하려고 하기보다는, 재사용, 확장성, 추상화의 키워드를 핵심 컨셉으로 "필요에 따라서 리팩토링" 해나가면 좋겠습니다.
대부분의 개발 업무는 자바(Java), 자바스크립트(JavaScript), PHP, C# 등의 대중화된 기술을 요구한다. 하지만 소프트웨어 수요가 발전하고 증가하면서 새롭고 덜 보편적인 언어가 인기를 얻어가고 있기도 하다. 이들 중에는 개발자들에게 특정 업무를 위한 중요한 도구를 제공하는 것들도 있다.
향후 어떤 언어가 인기를 얻게 될지 예상하기가 어렵고 많은 언어들이 한 동안 다양한 방식으로 활용되겠지만 상위 5개 언어 외에도 다양한 언어들의 인기가 지속적으로 상승할 전망이다. 앞으로 기업 내에서 더 큰 역할을 감당할 것으로 보이는 8가지 언어에 대해 알아본다.
1. 타이프스크립트(TypeScript) 타이프스크립트는 2017년 초부터 점차 인기가 증가한 언어다. 기술 전문지레드몽크(RedMonk)의 랭킹에 이런 상황이 반영됐고 깃허브(GitHub) 랭킹에서는 17점을 얻었으며 1분기 만에 얼랑(Erlang) 및 러스트(Rust)를 따라잡았다.
‘확장되는 자바스크립트’('JavaScript that scale)로 설명되는 타이프스크립트는 모든 변수에 유형을 추가하여 보안 강화를 추구했다. 가장 큰 장점은 개발자들이 앵귤러(Angular)를 활용할 수 있다는 점이다. 이는 타이프스크립트로 작성한 웹 애플리케이션 개발을 위한 프레임워크다. 하지만 앵귤러를 사용하기 위해 타이프스크립트를 사용할 필요는 없다.
2. R R은 통계 컴퓨팅을 위한 오픈소스 소프트웨어 환경을 제공한다. 1993년에 등장한 R은 데이터 마이닝(Data Mining), 통계학자, 학자 등 데이터 중심적인 사고와 직업에 이어 큰 인기를 누렸다. 하둡(Hadoop) 등의 거대 기술과 경쟁할 수는 없지만 데이터 서브셋 분석을 위한 단순하고 효과적인 도구가 될 수 있다.
3. 코틀린(Kotlin) 컴파일링(Compiling)이 신속하고 자바와 함께 구동되는 코틀린은 JVM(Java Virtual Machine)에서 동작하며 자바스크립트 소스 코드로 컴파일할 수 있는 정적 유형 프로그래밍 언어이다. 러시아의 소프트웨어 개발 기업 제트브레인스(JetBrains)가 개발한 코틀린은 핀터레스트(Pinterest), 에버노트(Evernote), 우버(Uber), 코세라(Coursera) 등에서 사용되고 있다.
4. 스위프트(Swift) 스위프트는 2014년 애플(Apple)의 WWDC 컨퍼런스에서 처음 등장했다. OSX 및 iOS 개발을 위한 오브젝티브 C(Objective-C) 언어를 대체하기 위한 목적을 가진다. 애플은 2015년 12월 아파치 라이선스에 기초해 해당 언어를 오픈소스화했다. 즉, 모든 소스 코드를 편집할 수 있으며 애플이 아니더라도 프로그램을 개발할 수 있다.
현대적 언어인 루비(Ruby) 및 파이썬(Python)과 유사한 스위프트는 출시 이후 급성장을 구가했다고 레드몽크의 분석가 스티븐 오그레디(Stephen O’Grady)가 평가했다. 한편 애플은 스위프트에 대해 “안전한 프로그래밍 패턴을 도입하며 현대적인 기능을 추가하여 프로그래밍이 더 쉽고 유연하며 재미있다”라고 표현하고 있다.
5. 러스트(Rust) 모질라(Mozilla)가 개발한러스트1.0은 2014년에 공개된 이후 수 년 동안 지속적으로 개발되어온 언어다. 모질라에 따르면 C 및 C++과 유사하며 “성능, 병행화, 메모리 안전성에 초점을 둔 새로운 프로그래밍 언어”다.
레드몽크의 오그레디는 최근 “처음부터 언어를 구축하고 현대적인 프로그래밍 언어 디자인의 요소를 통합함으로써 러스트의 개발자들은 전통적인 언어들이 처리해야 하는 많은 “앙금”(하위 호환성 요건)을 피하고 있다”라며 “이 언어가 여러 부문의 개발자들의 관심을 얻고 있다는 경험적 증거가 누적되고 있다”라고말했다.
6. 고(Go) 이 오픈소스 언어는 자신이 기반하고 있는 자바와 C 등의 좀 더 자리를 잡은 언어들보다 좀더 빠르고 사용이 쉬운 특성을 지닌다.
BB부터 사운드클라우드(SoundCloud), 페이스북부터 영국 정부가 시상한 GOV.UK 사이트까지 여러 조직이 이 언어를 사용하고 있다. 또한 기업 소프트웨어 스타트업 도커(Docker)도 사용하고 있다.
개발측은 고에 대해 “해석된 동적 유형화 언어의 프로그래밍 편의성과 정적 유형의 컴파일된 언어의 효율성 및 안전성을 융합하려는 시도다”라고 말했다.
7. 해스켈(Haskell) 해스켈은 자칭 ‘진보한 순수 함수형 프로그래밍 언어’(advanced purely-functional programming language)다. 첫 사양은 1990년에 공개됐다. 유형 추론(type inference) 및 ‘느긋한 평가’(lazy evaluation)를 갖춘 타입 시스템이 특징이다. 학계에서 주로 사용되고 있지만 AT&T, BAE 시스템즈(BAE Systems), 페이스북, 구글의 프로젝트 등 산업적인 용도로도 활용되고 있다. 2016년, 한 그룹이 이 언어의 2020 버전 컴파일링을 개시한 바 있다.
8. 클로저(Clojure) 2009년에 출시된 클로저는 리스프(Lisp) 프로그래밍 언어의 방언으로, 함수 프로그래밍에 중점을 둔 범용 언어다. 모드를 데이터로 처리하며 다른 ‘리스프’처럼 매크로(Macro) 시스템이 있다. 월마트(Walmart), 퍼펫 랩스(Puppet Labs), 기타 다양한 대형 소프트웨어 기업들이 이를 성공적으로 활용하고 있다. ciokr@idg.co.kr
JUnit개발 가이드는 이클립스 + springMVC + maven 개발환경 기반으로 작성하였다.
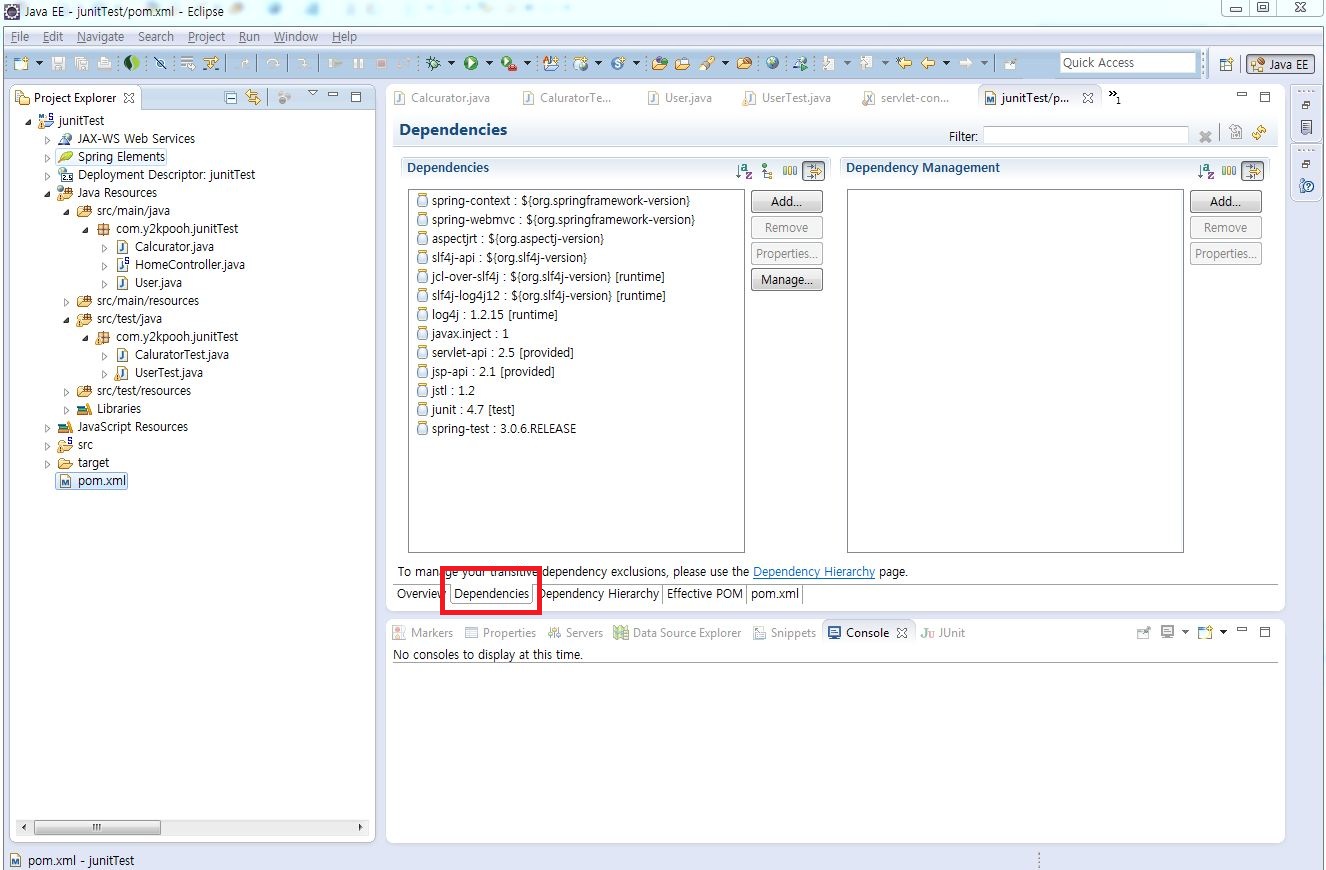
2.1 JUnit 라이브러리 추가 JUnit을 사용하려면 프로젝트에 JUnit 라이브러리가 필요하다. Maven프로젝트는 의존관계 설정이 쉽게 되어 기존 프로젝트에서 처럼 개발자가 해당 라이브러리를 찾는 수고를 덜어준다. Project Object Model(POM.xml) 에서 아래 그림1과 같이 Dependencies탭에서 JUnit을 찾아 추가를 하면 된다.
그림1
또는 직접 POM.xml에 dependencies element에 JUnit dependency를 아래와 같이 직접 추가할 수도 있다.
위와 같이 추가를 하게 되면 Maven 프로젝트 Install시 해당 라이브러리가 그림2와 같이 로컬 저장소에 저장하게 된다.
그림2
그림3
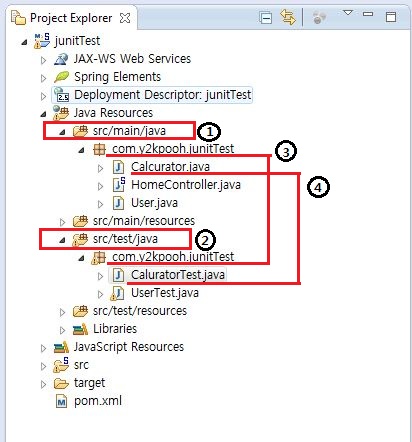
2.2 프로젝트 패키지 구성
JUnit테스트를 하기 위해서는 테스트 대상 클래스와 테스트 클래스는 같은 패키지 내에 있어야 한다. Maven 프로젝트를 생성하게 되면 Maven 관례에 따라, 그림3과 같은 프로젝트 템플릿이 기본적으로 생성된다. 그림3의 ① 디렉토리 /src/main/java/는 자바 코드를 보관하고 단위 테스트의 소스는 ② 디렉토리/src/test/java/ 디렉토리에 보관한다. ③ 테스트 하고자 하는 클래스가 포함된 패키지명과 동일하게 테스트 클래스를 포함하는 패키지도 동일하게 구성한다. ④ 테스트 대상 클래스와 테스트 클래스의 생성 예이다.
3. JUnit 테스트 클래스 작성
3.1 간략한 계산기 클래스 테스트
그림3의 프로젝트 패키지 구성에서 /src/main/java/ 디렉토리에 Calurator.java 클래스를 아래와 같이 작성한다.
package com.y2kpooh.junitTest;
public class Calcurator { public double sum(double a, doubleb){ return a + b; } }
위 Calcurator클래스는 double형의 두개의 파라메터를 받아 두 파라메터의 합을 구하여 double형으로 리턴해주는 sum 메서드를 가지고 있다. 물론 위 클래스는 문제가 될리 없는 간단한 프로젝트이나 테스트 클래스 작성에 이해를 돕기 위함이다.
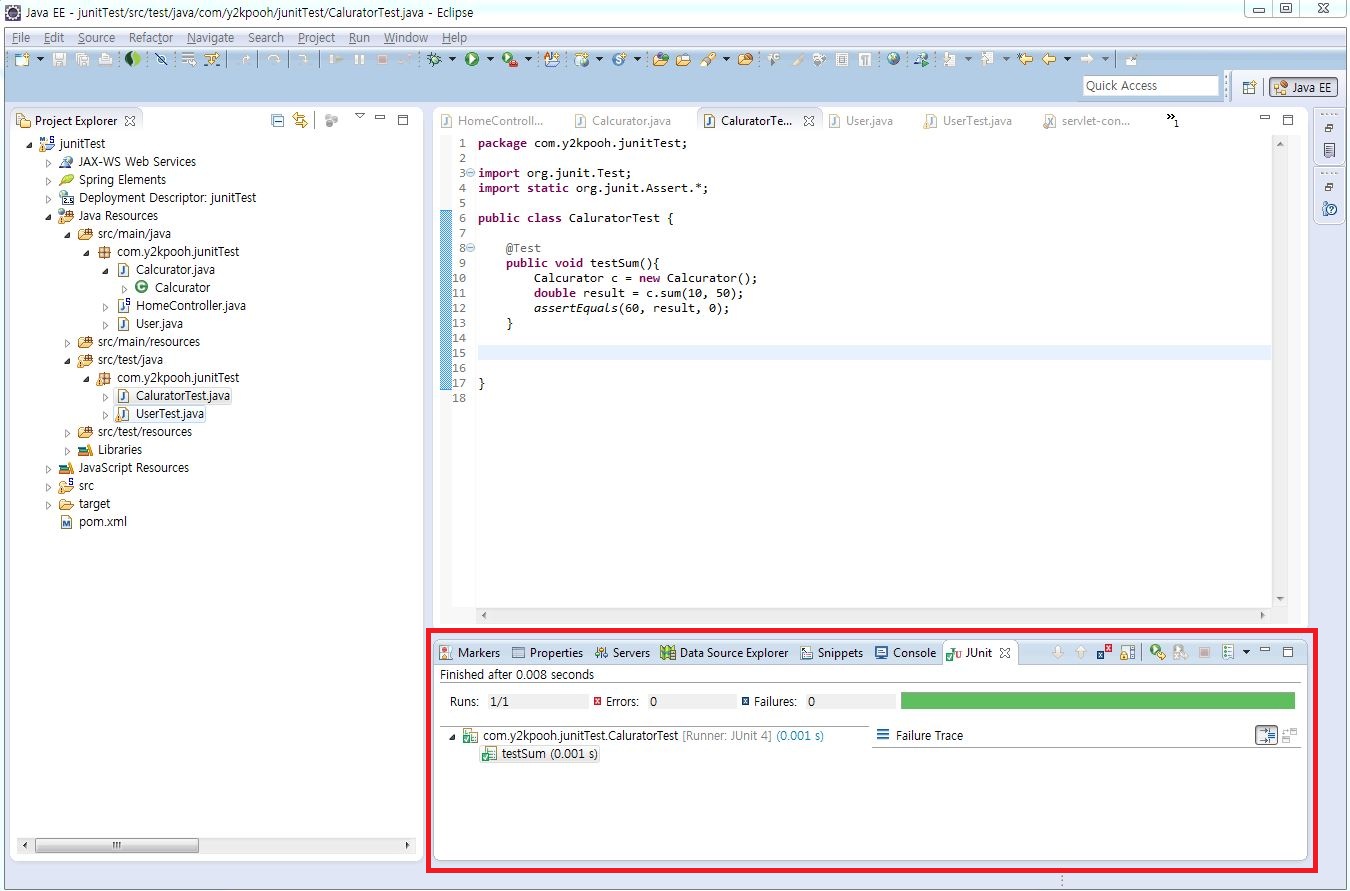
Calurator클래스 작성 후 해당 클래스를 테스트 하기 위한 테스트 클래스를 작성해보자. 그림3의 프로젝트 패키지 구성에서 /src/test/java/ 디렉토리에 CaluratorTest.java 클래스를 아래와 같이 작성한다.
public class CaluratorTest { ← ① @Test ← ② public void testSum(){ Calcurator c = new Calcurator(); double result = c.sum(10, 50); ← ③ assertEquals(60, result, 0); ← ④ } }
① 테스트 클래스는 반드시 public으로 선언해야 하며 클래스명은 관례에 따라 테스트클래명 + Test 끝나는 이름으로 사용된다. JUnit 3에서는 TestCase클래스를 상속받아 사용해야 했으나 JUnit 4에서는 상속받지 않아도 된다. (이 문서는 JUnit 4를 기반으로 작성되었다.) ② @Test 어노테이을 선언하여 testSum 메서드가 단위 테스트 메서드임을 선언하였다. 클래스명과 마찬가지로 테스트 메서드는 test + 테스트메서드명으로 선언한다. @Test 어노테이션을 선언한 메서드는 JUnit이 알아서 실행을 해준다. ③ Calcurator 클래스의 인스턴스를 선언하여 sum 메서드에 10, 50 인자값을 세팅하여 result변수에 결과값을 리턴 받는다. ④ JUnit 프레임워크에의 Assert 클래스의 정적 메서드인 assertEquals를 이용하여 테스트 결과 값을 확인한다. assertEquals(expected, actual, delta)는 assertEquals(예상값, 실제값, 허용오차)
CalcuratorTest 클래스 테스트 결과 그림4와 같이 테스트 성공 결과가 나온다.
그림4
3.2 JUnit assert 주요 메서드 및 사용예시
assert 메서드
설명
assertArrayEquals(a, b);
배열 A와 B가 일치함을 확인한다.
assertEquals(a, b);
객체 A와 B가 일치함을 확인한다.
assertSame(a, b);
객체 A와 B가 같은 객임을 확인한다. assertEquals 메서드는 두 객체의 값이 같은가를 검사는데 반해 assertSame메서드는 두 객체가 동일한가 즉 하나의 객인 가를 확인한다.(== 연산자)
Spring 기반의 테스트 코드 작성을 위해 테스트 클래스 상단에 @RunWith(SpringJUnit4ClassRunner.class) 구문을 추가한다. Spring 프레임워크 context 파일을 테스트 수행시에도 동일하게 로딩하기 위해 @ContextConfiguration(locations={"file:WebContent/WEB-INF/classes/applicationContext*.xml"}) 과 같은 형태로 프로젝트의 스프링 설정파일을 설정해 준다.
메서드 수행시간 제한하기
@Test(timeout=5000)
단위는 밀리초이며 이 메서드가 결과를 반환하는데 5,000밀리초가 넘긴다면 테스트는 실패한다.
Exception 테스트
@Test(expected=RuntimeException.class)
해당 클래스는 RuntimeException이 발생해야 한다. 만약 테스트에서 RuntimeException이 발생하지 않을 경우 실패한다.
테스트 건너뛰기
@Test(timeout=5000) @Ignore(value=”여기는 테스트 안할거야”)
@Ignore 어노테이션을 추가하면 해당 메서드는 테스트를 건너뛰게 되며 JUnit4는 성공 및 실패 개수와 함께 건너뛴 테스트 수도 포한된 결과 통계를 제공한다.
초기화 및 종료
@Before [...] @After [...]
@Before 어노테이션이 선언된 메서드는 해당 테스트 클래스의 인스턴스, 객체를 초기하 하는 작업을 한다. @After 어노테이션이 선언된 메서드는 해당 테스트 실행 후 실행된다. 해당 @Before, @After 어노테이션 이외 @BeforeClass, @AfterClass도 있으며 이는 static 메서드와 동일한 형태로 테스트 클래스 실행 시 한번만 실행된다.
4. 목 객체를 활용한 테스트
4.1 목(Mock) 객체란? 어플리케이션플리케이션을 개발하다보면, 테스트 대상 코드가 다른 클래스에 종속되어 있을 때가 종종 있다. 그 클래스가 다시 다른 클래스에 종속되고, 역시 또 다른 클래스에 종속되기도 한다. JDBC를 통해 데이터베이스에 의존하는 JAVA EE 애플리케이션, 파일 시스템을 사용하는 어플리케이션, HTTP나 SOAP 등의 프로토콜로 외부 리소스에 접근하는 어플리케이션들을 예로 들 수 있다. 특정 런타임 환경에 의존적인 어플리케이션을 단위 테스트하는 것은 꽤나 고된 일이다. 테스트는 안정적이어야 하고, 반복적으로 수행해도 매번 동일한 결과를 내야 한다. 따라서 테스트를 올바로 수행하기 위해서는 환경을 제어할 수 있어야 한다. 예를 들어 다른 회사에 제공하는 웹 서버에 HTTP 커넥션을 맺는 어플리케이션을 제작하는 경우 그 외부 서버를 개발 환경 안에 가져올 수 없다. 테스트를 작성하고 돌려 보려면, 결국 서버를 시뮬레이션하는 방법이 필요하다. 또는 팀 단위 프로젝트에서 내가 맡은 부분을 테스트해보려 할때 다른 부분이 아직 준비되지 않았다면... 가짜를 만들어 미처 준비되지 못한 부분을 시뮬레이션할 수 있다. 이 처럼 가짜 객체를 제공하는 테스트 방식으로 목 객체를 사용할 수 있다.(스텁방식도 있다.)
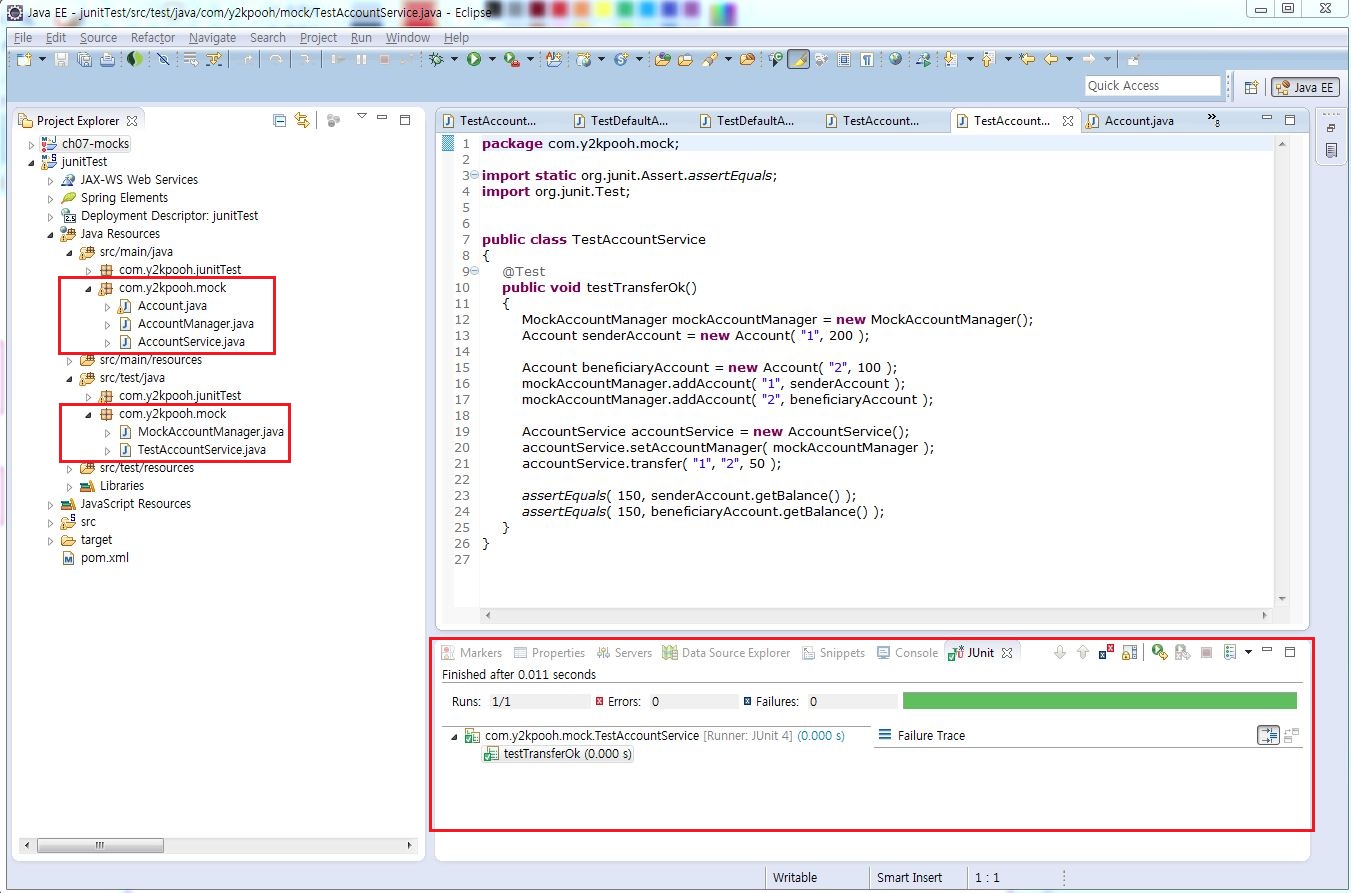
4.2 목 객체를 활용해 단위 테스트 하기 한 은행 계좌에서 다른 계좌로 송금하는 단순한 테스트 케이스이다. 위 계좌 송금 프로세스를 기능 테스트 하기 위해서는 AccountService를 테스트 하기 위해서는 우선 데이터베이스를 세팅한 후 테스트 데이터를 채워넣는 작업을 진해하여야 한다. 목 객체를 활용하면 아직 작성되지 않은 코드를 테스트할 수 있다. 단 인터페이스가 정의되어 있어야 한다.
Account.java 계좌 ID와 잔고를 갖는 Account 객체
package com.y2kpooh.mock;
public class Account { /** * 계좌 아이디 */ private String accountId;
public class TestAccountService { @Test public void testTransferOk() { //테스트를 하기위한 객체 생성 및 준비 MockAccountManager mockAccountManager = new MockAccountManager(); Account senderAccount = new Account( "1", 200 ); Account beneficiaryAccount = new Account( "2", 100 ); mockAccountManager.addAccount( "1", senderAccount ); mockAccountManager.addAccount( "2", beneficiaryAccount ); AccountService accountService = new AccountService(); accountService.setAccountManager( mockAccountManager ); // 테스트 수행 accountService.transfer( "1", "2", 50 ); // 결과 검증 assertEquals( 150, senderAccount.getBalance() ); assertEquals( 150, beneficiaryAccount.getBalance() ); } }
테스트 결과 및 프로젝트 패키지 구성화면
그림5
4.3 목 프레임워크 활용하기 목 객체를 활용하여 테스트 하려면 목 객체를 직접 개발자가 만들어야 한다. 바쁜 프로젝트 일정에 테스트하려고 목 객체를 만들자니 배보다 배꼽이 큰 것 같은 생각이 들지도 모른다. 역시나 천재들이 만들어 놓은 훌륭한 목 프레임워크가 존재 한다. EasyMock과 JMock이 있으며 해당 라이브러리만 세팅하면 쉽게 목 객체를 활용할 수 있다.
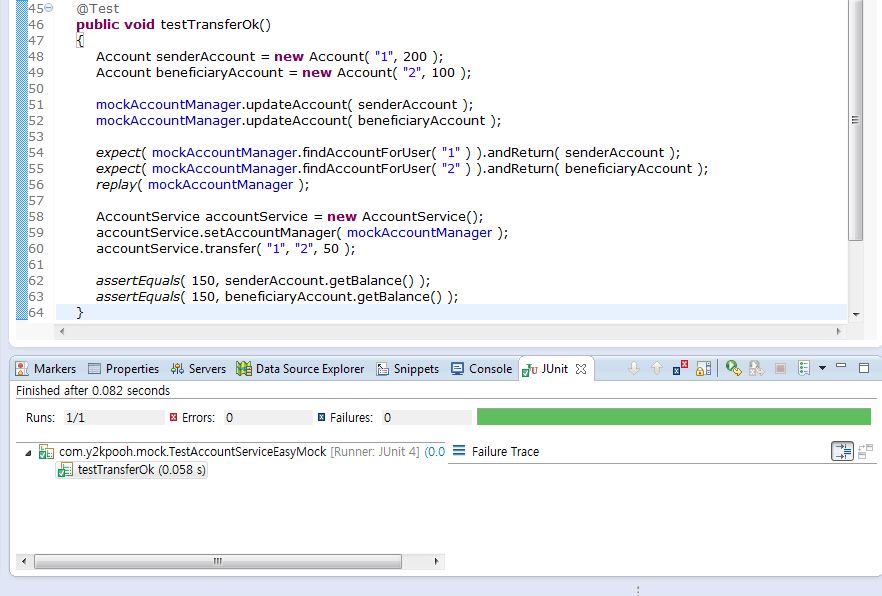
테스트를 하고자 하는 클래스 AccountService는 이미 완성되어 있으며 해당 클래스를 테스트 하기 위해서는 AccountManager에 대한 Implement Class가 없다. 이 AccountManager에 대한 클래스를 EasyMock을 이용해서 테스트 가능하다. (4.2 목 객체를 이용한 테스트 케이스에서는 AccountManager의 Implement Class로 MockAccountManager 클래스를 작성하여 테스트가 가능했었다. 여기서 꼭 기억할 것은 목 객체를 이용하여 테스트하기 위해서는 꼭 인터페이스가 정의되어 있어야 한다.)
바로 위에서 REST에 대해서 알아본다고 하였지만, REST의 정의와 같은 것은 생략할 예정입니다. 진짜로 이글에서 다룰 것은 실제 RESTFul한 API를 작성할 때 도움될만한 것들을 공부합니다. 또한 여러가지 규칙이 있지만 어느 규칙이 진짜이고, 표준화 된것이 없기때문에(이런것으로 알고있습니다.) 실제 많은 사이트들이 약간씩은 다른 형태로 REST API를 운영하고있습니다. 이 글에서도 필자가 중요하다고 생각하고 직관적이라고 생각하는 요소들을 선택 하여 소개 또는 설명 할 예정입니다.
요즘은 예전과 달리 소비를 위한 장비 및 프로그램이 다양합니다. 반대로 말하면 예전에는 어떠한 인터넷 컨텐츠를 소비하기위한 장비나 프로그램이 몇개 없었습니다. 그렇기때문에 서버와 클라이언트가 거의 1:1이였습니다. 그러나 요즘은 역시 서버는 1인데 클라이언트가 굉장히 다양해졌습니다. 안드로이드는 OS 버전도 굉장히 다양하고 단말기마다 굉장히 다른 특성을 갖기도 합니다. 또 IOS도 있고, 컴퓨터 브라우져의 종류도 많아졌죠.
그래서 예전처럼 하나의 클라이언트를 위한 서버를 구성하는건 비효율적인 일이 되어버렸습니다. 하나의 서버로 여러대의 클라이언트를 대응하도록 할때 필요한것이 RESTFul API입니다.
URI 설계하기
일단 URI(Uniform Resource Identifier)란 영어 약자를 풀어보면 '균등한 리소스 식별자'정도로 할 수 있습니다. 말그대로 인터넷의 어떠한 리소스를 식별하기 위해서 만들어진 것입니다. 잘 감이 안오는데 중간중간 특성들을 이야기하면서 내용을 보강하겠습니다.
http://www.example.com:80/users/1?q=abc#title
|________________________|_______|__________|
1 2 3
URI는위와같이 크게 3부분으로 나뉘어져있습니다.
rfc3986에서는 1번부분(host와 port)을 제외한 2번 3번 부분은 대소문자를 구분하도록 하였습니다.
위 예제에서 a와 b만 같은 리소스이고 나머지 조합은 전부 다른 리소스입니다. 그러므로 대소문자를 섞어서 사용하는건 혼란을 가져올 수 있으므로 지양해야겠습니다. 그래도 URI에 사람이름과 같은 고유명사가 들어갈 수 도있죠.. 이땐 대문자를 쓰고싶은데... 사용해도 되긴합니다만 대소문자가 구분된다는걸 이해하셔야 합니다. 위 설명과 중복되긴 하지만 다시한번 언급하겠습니다.
경로(path)에 공백(띄어쓰기)가 들어갈땐 경우에따라 띄어쓰기 대신 %20이 쓰일때가 있습니다. 이런건 보기에 별로 좋지 않기때문에 많은 사람들이 밑줄(_, underscore) 또는 하이픈(-, hyphen)을 사용하여 공백을 대체합니다. 여기서 권장하는건 하이픈만 사용하자 입니다. 보통 밑줄은 링크가 걸린부분에 표시되는데 그것과 중복되면 리소스로써의 밑줄은 가려질 수도있기때문에 하이픈을 사용하자.
확장자를 사용하지 말자
기존의 많은 URI들이 확장자를 포함하고 있습니다. 하지만 REST API를 설계할때에는 확장자는 사용하지 않는게 좋겠습니다. 확장자를 사용하지 않으면 리소스가 더 유연해집니다. 어째든 확장자를 사용하지 않는다면 기존에 REST API를 접해보지 않는 사람들은 이런 의문을 갖을 수 있습니다? 결론적으로 Accept header를 사용해야 합니다. 예를들어 내용이 Hello,World인 파일이 있습니다. 서버를 기존방식대로 설계한다면 해당 파일은 http://remotty.com/hello.txt와 같이 요청하여 응답받을 것입니다. 기존의 방식은 분명하게 파일의 형태가 txt로 고정되어있습니다. csv 형태로도 제공하려면 http://remotty.com/hello.csv URI도 준비해야 할것이고, 서버엔 hello.txt와 hello.csv 두개의 파일이 존재 하게 될것입니다. http://remotty.com/hello.txt와 http://remotty.com/hello.csv는 분명하게 다른 리소스를 식별하는 URI이지만, 실제론 하나의 리소스를 가르키고 있습니다. 이것은 비 효율적입니다. 리소스가 한개라면 URI도 한개여야합니다.
REST API에서는 http://remotty.com/hello에 대한 대응만 해놓고, 해당 요청이 왔을때 Accept header를 적절히 파싱(parsing)하여 클라이언트(client)가 요청한대로 응답해주면 됩니다.
REST API로 구현했을땐
GET /hello HTTP/1.1
Host: remotty.com
Accept: text/plain
또는
GET /hello HTTP/1.1
Host: remotty.com
Accept: text/csv
Accept를 좀더 적극적으로 활용한다면 이렇게도 가능합니다.
GET /hello HTTP/1.1
Host: remotty.com
Accept: text/csv,text/html;q=0.5,application/xml;q=0.6,text/plain;q=0.9,application/pdf,*/*;q=0.3
Accept header은 클라이언트가 자신이 선호하는 media type을 서버에 보내는 것입니다. 서버에 위 예제와 같은 요청이 왔다면 가장먼저 우선순위는 다음과 같습니다.
text/csv
application/pdf
text/plain;q=0.9
application/xml;q=0.6
text/html;q=0.5
*/*;q=0.3
q가 생략된것은 자동으로 1로 설정되며, q의 범위는 0부터 1입니다. 서버가 판단하여 csv로 응답을 할 수 있다면 csv로 응답을 하고 csv가 준비가 되지 않았다면 그다음 우선순위인 pdf로 pdf도 준비되지 않았다면 계속 다음으로 넘어가다가 서버가 응답할수있는 media type가 Accept에 명시되지 않았다면 http status code 406과 body엔 응답 가능한 media type를 명시하여 응답하여야 합니다. 더 자세한 내용은 http content negotiation으로 검색하시어 저도 좀 알려주시기 바랍니다.
위와 같이 Accept header를 적절히 잘 사용하면 하나의 URI로 클라이언트의 요청에 대한 응답을 좀더 유연하게 할 수 있습니다.
CRUD는 URI에 사용하면 안된다
과거에 GET, POST만 사용하였을땐 CRUD를 URI에 표시해주어야 했습니다.
예를들면
GET /posts/13/delete HTTP/1.1
POST /posts/write HTTP/1.1
GET /delete?id=55 HTTP/1.1
하지만 당신은 이제부터 REST API를 설계할 수 있습니다. 뒷부분에 나오는 HTTP Method의 알맞은 역할을 참조하여 적절한 Method를 사용하여 CRUD는 URI에 사용하지 않기로 합시다.
컬렉션과 도큐먼트
이 글을 보기전 REST 관련된 글을 본적이 있다면 컬렉션(collection)이라고 이야기하는 도큐먼트(document)들의 집합을 들어보았을 겁니다. 도큐먼트는 우리말로 문서로 이해해도 되고, 정보라고 이해해도 무관합니다. 도큐먼트는 엘리먼트(element)라고도 하더라고요. 컬렉션은 정보(문서)들의 집합이 이라고 할 수 있겠네요. 컬렉션과 도큐먼트는 모두 리소스라고 표현할 수 있으며 URI에 나타납니다.
http://www.remotty.com/sports는 컬렉션입니다. sports컬렉션에 soccer도큐먼트가 있는거고요. 또 soccer도큐먼트에 player이라는 컬렉션이 존재하는겁니다! players 컬렉션에 뭐 등번호가 13번인 선수가 있나봅니다. 여기서 13은 도큐먼트이고요. 아시겠죠...? 조금 더 이야기 해보겠습니다. soccer 도큐먼트와 동일한 수준의 다른 도큐먼트는 뭐가 있을까요...? baseball, marathon 등이 있겠네요. 그 하위의 players의 컬렉션과 동일한 수준의 컬렉션은 뭐가있을까요...? rules, leagues 등이 있겠네요. 이제 뭔지 아시겠죠...?
여기서... 중요한 법칙이랄꺼 까진 없지만 뭔가 있습니다. 바로 컬렉션은 복수로 사용하네요. 어쩌면 당연하지만 직관적인 REST API를 위해선 단수 복수도 정확하게 지켜주면 좋겠습니다. 요즘은 한글이 URI에 많이 들어가는데 players는 선수들로 하면 되려나요...?
HTTP Method의 알맞은 역할
HTTP Method는 여러가지가 있지만 REST API에서는 4개 혹은 5개의 Method만 사용됩니다. POST, GET, PUT, DELETE 이 4가지의 Method를 가지고 CRUD를 할 수 있습니다. 그러나 REST API에서 사용되는 개수는 4개 혹은 5개라고 한 이유는 PATCH를 포함하면 5개가 됩니다.
각 Method마다 올바른 역할이 있습니다. 아래 표를 보면서 이해를 높이겠습니다.
+--------------------------------------+------+-----+-----+--------+
| URI | POST | GET | PUT | DELETE |
+--------------------------------------+------+-----+-----+--------+
| http://www.remotty.com/sports | 1 | 2 | - | - |
+--------------------------------------+------+-----+-----+--------+
| http://www.remotty.com/sports/soccer | - | 3 | 4 | 5 |
+--------------------------------------+------+-----+-----+--------+
text table generator에서 만든 text table인데 한글을 사용하면 깨지므로... :(
번호를 이용하여 설명하겠습니다.
현재 리소스 보다 한단계 아래에 리소스를 생성합니다. POST Method를 통해 해당 URI를 요청하면 sports 컬렉션에 알맞은 soccer 또는 baseball과 같은 도큐먼트 리소스를 생성합니다.
현재 리소스를 조회합니다. 보통 컬렉션 리소스를 조회하게되면 하위의 도큐먼트들의 목록과 아주 간단한 정보들을 가져옵니다.
현재 리소스를 조회 합니다. 도큐먼트 리소스를 조회하게되면 해당 도큐먼트에 대한 자세한 정보들을 가져옵니다.
현재 리소스를 수정합니다. soccer에 대한 정보를 수정하게 됩니다.
현재 리소스를 삭제합니다. DELETE Method를 이용하여 현재 URI를 호출하면 sports 컬렉션에서 soccer 도큐먼트가 삭제됩니다.
요즘은 정말 다양한 장비들이 존재합니다. 크기 역시 다양합니다. 그래서 요즘 작은 화면의 기기로 포털사이트를 접속해보면 어느 형태로든 m이 붙은걸 볼수 있습니다. 아마 mobile에서 맨앞의 m인것같은데, 화면이 작은 장비에서는 800*600이 넘어가는 사이트를 돌아다니는건 정말 피곤한 일입니다. 그래서 작은 화면용 페이지가 필요한 이유입니다. 네, 여기까지는 좋습니다. 제가 이 부분에서 소개해드리려는 header는 User-Agent입니다. 그리고 결론적으로 말씀드리고 싶은 내용은 http://m.remotty.com/abc 또는 http://www.remotty.com/m/abc처럼 사용하지 말자 입니다.
뭐가 문제인지 감이 오시나요? 다국어 지원을 Accept-Language에 맡긴다면 URI는 그대로인데, 사용자의 환경에 따라 알맞은 언어로 응답할 수 있습니다. 물론 Accept-Language만 가지고 다국어를 하면 조금 어색할 수 있을꺼 같습니다. 사용자가 원하는 언어를 설정하게하여 해당 언어를 세션 또는 쿠키 등에 저장하여 보여줄 언어를 선정할때 우선순위를 약간 조정하여 보여주는게 좋은 방법일꺼 같습니다.
지금 약간 이글의 확장자를 사용하지 말자와 반응형 웹에서의 REST랑 약간 비슷한 느낌인데요, 모두 결론은 URI는 리소스를 식별하기 위해서 사용되었지, 리소스가 어떻게 보여지느냐는 별도의 header을 이용하여 처리하였습니다. 이 점을 생각하면서 다른 문제들도 좀더 REST하게 설계해야겠습니다.
응답 상태 코드
rfc2616을 살펴보면 많은 종류의 상태코드가 존재합니다. 상태코드를 적절히 잘 사용하면 클라이언트에게 많은 정보를 줄 수 있습니다.
성공
200 - 클라이언트의 요청을 정상적으로 수행하였을때 사용합니다. 응답 바디(body)엔 요청과 관련된 내용을 넣어줍니다. 그리고 200의 응답 바디에 오류 내용을 전송하는데 사용해서는 안된다고 합니다. 오류가 났을땐 40x 응답 코드를 권장합니다.
201 - 클라이언트가 어떤 리소스 생성을 요청하였고, 해당 리소스가 성공적으로 생성되었을때 사용합니다.
202 - 클라이언트의 요청이 비동기적으로 처리될때 사용합니다. 응답 바디에 처리되기까지의 시간 등의 정보를 넣어주면 좋다고 합니다.
204 - 클라이언트의 요청응 정상적으로 수행하였을때 사용합니다. 200과 다른점은 204는 응답 바디가 없을때 사용합니다. 예를들어 DELETE와 같은 요청시에 사용합니다. 클라이언트의 리소스 삭제요청이 성공했지만 부가적으로 응답 바디에 넣어서 알려줄만한 정보가 하나도 없을땐 204를 사용합니다.
실패
400 - 클라이언트의 요청이 부적절할때 사용합니다. 요청 실패시 가장 많이 사용될 상태코드로 예를들어 클라이언트에서 보낸 것들이 서버에서 유효성 검증(validation)을 통과하지 못하였을때 400으로 응답합니다. 응답 바디에 요청이 실패한 이유를 넣어줘야 합니다.
401 - 클라이언트가 인증되지 않은 상태에서 보호된 리소스를 요청했을때 사용하는 요청입니다. 예를들어 로그인(login)하지 않은 사용자가 로그인했을때에만 요청 가능한 리소스를 요청했을때 401을 응답합니다.
403 - 사용자 인증상태와 관계 없이 응답하고싶지 않은 리소스를 클라이언트가 요청했을때 사용합니다. 그러나 해당 응답코드 대신 400을 사용할 것을 권고합니다. 그 이유는 일단 403 응답이 왔다는것 자체는 해당 리소스가 존재한다는 뜻입니다. 응답하고싶지 않은 리소스는 존재 여부 조차 감추는게 보안상 좋기때문에 403을 응답해야할 요청에 대해선 그냥 400이나 404를 응답하는게 좋겠습니다.
404 - 클라이언트가 요청한 리소스가 존재 하지 않을때 사용하는 응답입니다.
405 - 클라이언트가 요청한 리소스에서는 사용 불가능한 Method를 이용했을때 사용하는 응답입니다. 예를들어 읽기전용 리소스에 DELETE Method를 사용했을때 405 응답을 하면 됩니다.
기타
301 - 클라이언트가 요청한 리소스에 대한 URI가 변경 되었을때 사용합니다. 응답시 Location header에 변경된 URI를 적어줘야 합니다.
순서가 약간 뒤죽박죽 작성된 느낌이 있네요. 사실 저도 RESTFul한게 좋은건지 나쁜건지 뭔지 아직도 잘 모르는 상태로 작성하였는데, 한가지 확실한건 REST라는 개념(?)이 널리 퍼지고 많은 API들이 RESTFul하다면 REST에서 다루는 내용들은 따로 문서화도 필요없이 자연스레 좀더 체계적인 느낌으로 API를 사용할 수 있을꺼 같은 느낌이 듭니다. 아직 미완성된 글이라 생각합니다. 틀린 내용이나 이해되지 않는 내용이 있으시면 댓글이나 기타 편하신 방법을 통해 적극적으로 글을 완성해주시길 바랍니다.