html 안에 script 태그를 어느 위치에 삽입하는것이 가장 좋을까? 문득 궁금해서 찾아보았습니다. 다음은 stackoverflow 에서 가장 추천수가 많은 질문과 답변입니다. 발번역이므로 오역은 댓글로 지적받겠습니다 :)
HTML 문서에 자바 스크립트를 삽입 할 때 <script> 태그와 자바 스크립트를 넣을 수있는 가장 좋은 곳은 어디일까?
사람들은 자바스크립트를 <head> 섹션에 삽입하면 좋지 않다고 하지만, <body> 섹션의 시작 부분에 놓는 것 또한 나쁘다고 합니다. 왜냐하면 자바 스크립트는 페이지가 완전히 렌더링되기 전에 파싱되어야하기 때문입니다. 그럼 <body> 섹션의 끝에 <script> 태그를 놓는 방법만이 남은것 같아 보입니다. 그렇다면 <script> 태그를 넣을 수있는 가장 적합한 곳은 어디일까요?
브라우저가 웹 사이트를 로드 할 때 일어나는 일
HTML 페이지 가져 오기 (예 : index.html)
HTML 구문 분석을 시작합니다
파서는 외부 스크립트 파일을 참조하는 <script> 태그를 발견합니다.
브라우저가 스크립트 파일을 요청합니다. 한편 파서는 페이지의 다른 HTML을 구문 분석하는 것을 차단합니다.
잠시 후 스크립트가 다운로드 된 후 실행됩니다.
파서는 나머지 HTML 문서를 계속 파싱합니다.
4번은 좋지 않은 사용자 환경을 유발합니다. 웹 사이트는 기본적으로 모든 스크립트를 다운로드 할 때까지 로드를 중지합니다. 사용자는 웹 사이트가 로드 될 때까지 기다리는 것을 싫어합니다.
왜 이런 일이 일어날까요?
모든 스크립트는 document.write () 또는 다른 DOM 조작을 통해 자체 HTML을 삽입 할 수 있습니다. 이는 구문 분석기가 나머지 문서를 안전하게 구문 분석하기 전에 스크립트가 다운로드되고 실행될 때까지 기다려야 함을 의미합니다. 결국 스크립트는 자체 HTML을 문서에 삽입 할 수 있습니다.
그러나 대부분의 개발자는 문서가 로드되는 동안 더 이상 DOM을 조작하지 않습니다. 대신 문서를 수정하기 전에 문서가 로드 될 때까지 대기합니다.
브라우저가 my-script.js가 다운로드되고 실행될 때까지 문서를 수정하지 않는다는 것을 브라우저가 알지 못하기 때문에 파서가 구문 분석을 중단합니다.
고전적인 방법
이 문제를 해결하기위한 이전 접근법은 <body> 맨 아래에 <script> 태그를 두는 것이 었습니다. 이렇게하면 파서가 맨 끝까지 차단되지 않기 때문입니다.
이 접근 방식에는 자체적 인 문제가 있습니다. 브라우저는 전체 문서가 구문 분석 될 때까지 스크립트 다운로드를 시작할 수 없습니다. 큰 스크립트 및 스타일 시트가있는 더 큰 웹 사이트의 경우 가능한 한 빨리 스크립트를 다운로드 할 수있는 것이 성능 향상에 매우 중요합니다. 웹 사이트가 2초 내에 로드되지 않으면 사람들은 다른 웹 사이트로 이동할 것 입니다.
최적의 솔루션에서 브라우저는 가능한 한 빨리 스크립트 다운로드를 시작하는 동시에 문서의 나머지 부분을 파싱합니다.
현대적인 접근법
오늘날 브라우저는 스크립트의 비동기 및 지연 특성을 지원합니다. 이러한 속성은 스크립트가 다운로드되는 동안 계속 구문 분석을하는 것이 안전하다는 것을 브라우저에 알려줍니다.
자바스크립트는 프로토타입 기반 언어라고 불립니다. 자바스크립트 개발을 하면 빠질 수 없는 것이 프로토타입인데요. 프로토타입이 거의 자바스크립트 그 자체이기때문에 이해하는 것이 어렵고 개념도 복잡합니다.
하지만 프로토타입이 무엇인지 깨우친 순간 자바스크립트가 재밌어지고, 숙련도가 올라가는 느낌을 팍팍 받을 수 있습니다. 그럼 지금부터 프로토타입을 이해해봅시다.
Prototype vs Class
클래스(Class)라는 것을 한 번쯤은 들어보셨을겁니다. Java, Python, Ruby등 객체지향언어에서 빠질 수 없는 개념이죠. 그런데 중요한 점은 자바스크립트도 객체지향언어라는 것입니다. 이게 왜 중요하냐구요? 자바스크립트에는 클래스라는 개념이 없거든요. 대신 프로토타입(Prototype)이라는 것이 존재합니다. 자바스크립트가 프로토타입 기반 언어라고 불리는 이유이죠.
클래스가 없으니 기본적으로 상속기능도 없습니다. 그래서 보통 프로토타입을 기반으로 상속을 흉내내도록 구현해 사용합니다.
참고로 최근의 ECMA6 표준에서는 Class 문법이 추가되었습니다. 하지만 문법이 추가되었다는 것이지, 자바스크립트가 클래스 기반으로 바뀌었다는 것은 아닙니다.
어디다 쓰나요?
그럼 프로토타입을 언제 쓰는지 알아봅시다.
넌 이미 알고있다
자바스크립트에 클래스는 없지만 함수(function)와 new를 통해 클래스를 비스무리하게 흉내낼 수 있습니다.
function Person() { this.eyes = 2; this.nose = 1; }
자바스크립트 개발을 하시는 분이라면 아마 써보진 않았어도 최소한 본 적은 있을겁니다. 간단히 설명하자면 Person.prototype이라는 빈 Object가 어딘가에 존재하고, Person 함수로부터 생성된 객체(kim, park)들은 어딘가에 존재하는 Object에 들어있는 값을 모두 갖다쓸 수 있습니다. 즉, eyes와 nose를 어딘가에 있는 빈 공간에 넣어놓고 kim과 park이 공유해서 사용하는 것이죠. 이해되셨나요?
프로토타입을 깊게 파보면 엄청나게 복잡하지만 개발자가 사용하는 부분만 본다면 이게 거의 전부입니다. 하지만 개발자는 사용법만 알고있는게 아니라 언제나 왜? 를 생각해야합니다.
프로토타입이 왜 이렇게 쓰이는지 조금 더 깊게 알아보도록 하겠습니다.
Prototype Link와 Prototype Object
자바스크립트에는 Prototype Link 와 Prototype Object라는 것이 존재합니다. 그리고 이 둘을 통틀어 Prototype이라고 부릅니다. 프로토타입을 좀 안다는 것은 이 둘을 완벽히 이해하고 갖고 놀 수준이 되었다는 뜻입니다.
제가 프로토타입에 대해 공부하면서 중요하다고 생각되는 포인트가 몇 가지 있었습니다. 그 포인트들을 잘 이해하면서 보시기 바랍니다.
Prototype Object
모든 객체(Object)의 조상은 함수(Function)입니다.
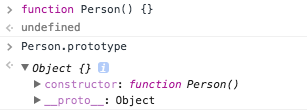
function Person() {} // => 함수
var personObject = new Person(); // => 함수로 객체를 생성
personObject 객체는 Person이라는 함수로부터 파생된 객체입니다. 이렇듯 언제나 객체는 함수로부터 시작됩니다. 여러분이 많이 쓰는 일반적인 객체 생성도 예외는 아닙니다.
var obj = {};
얼핏보면 함수랑 전혀 상관없는 코드로 보이지만 위 코드는 사실 다음 코드와 같습니다.
var obj = new Object();
위 코드에서 Object가 자바스크립트에서 기본적으로 제공하는 함수입니다.
Object도 함수다!
Object와 마찬가지로 Function, Array도 모두 함수로 정의되어 있습니다. 이것이 첫 번째 포인트입니다.
그렇다면 이것이 Prototype Object랑 무슨 상관이있느냐? 함수가 정의될 때는 2가지 일이 동시에 이루어집니다.
1.해당 함수에 Constructor(생성자) 자격 부여
Constructor 자격이 부여되면 new를 통해 객체를 만들어 낼 수 있게 됩니다. 이것이 함수만 new 키워드를 사용할 수 있는 이유입니다.
constructor가 아니면 new를 사용할 수 없다!
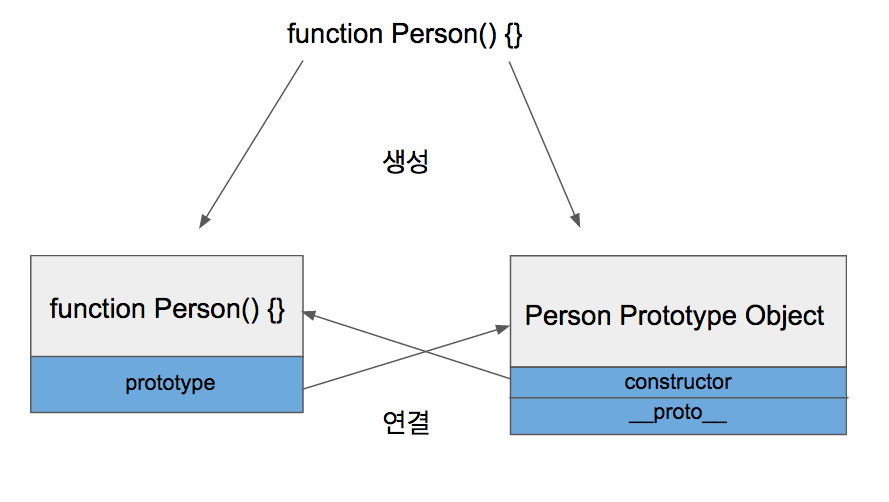
2.해당 함수의 Prototype Object 생성 및 연결
함수를 정의하면 함수만 생성되는 것이 아니라 Prototype Object도 같이 생성이 됩니다.
함수를 정의하면 이렇게 됩니다
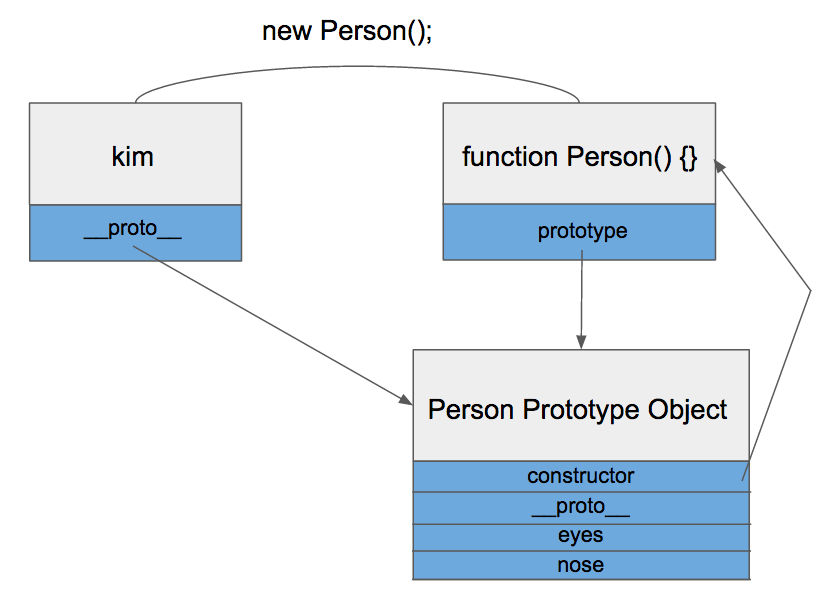
그리고 생성된 함수는 prototype이라는 속성을 통해 Prototype Object에 접근할 수 있습니다. Prototype Object는 일반적인 객체와 같으며 기본적인 속성으로 constructor와 __proto__를 가지고 있습니다.
prototype 속성으로 Prototype Object에 접근
constructor는 Prototype Object와 같이 생성되었던 함수를 가리키고 있습니다. __proto__는 Prototype Link입니다. 밑에서 자세히 설명합니다.
Prototype Object는 일반적인 객체이므로 속성을 마음대로 추가/삭제 할 수 있습니다. kim과 park은 Person 함수를 통해 생성되었으니 Person.prototype을 참조할 수 있게 됩니다.
Prototype Link를 보기 전에 Prototype Object를 어느 정도 이해하시고 보기 바랍니다. 함수가 정의될 때 이루어지는 일들을 이해하는 것이 두 번째 포인트, Prototype Object를 이해하는 것이 세 번째 포인트입니다.
Prototype Link
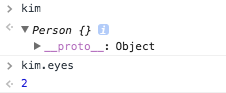
kim 객체는 eyes가 없는데 ??
kim에는 eyes라는 속성이 없는데도 kim.eyes를 실행하면 2라는 값을 참조하는 것을 볼 수 있습니다. 위에서 설명했듯이 Prototype Object에 존재하는 eyes 속성을 참조한 것인데요, 이게 어떻게 가능한걸까요??
바로 kim이 가지고 있는 딱 하나의 속성 __proto__가 그것을 가능하게 해주는 열쇠입니다.
prototype 속성은 함수만 가지고 있던 것과는 달리(Person.prototype 기억나시죠?) __proto__속성은 모든 객체가 빠짐없이 가지고 있는 속성입니다.
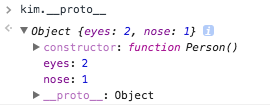
__proto__는 객체가 생성될 때 조상이었던 함수의 Prototype Object를 가리킵니다. kim객체는 Person함수로부터 생성되었으니 Person 함수의 Prototype Object를 가리키고 있는 것이죠.
드디어 __proto__를 공개합니다
__proto__를 까보니 역시 Person 함수의 Prototype Object를 가리키고 있었습니다.
객체, 함수, Prototype Object의 관계
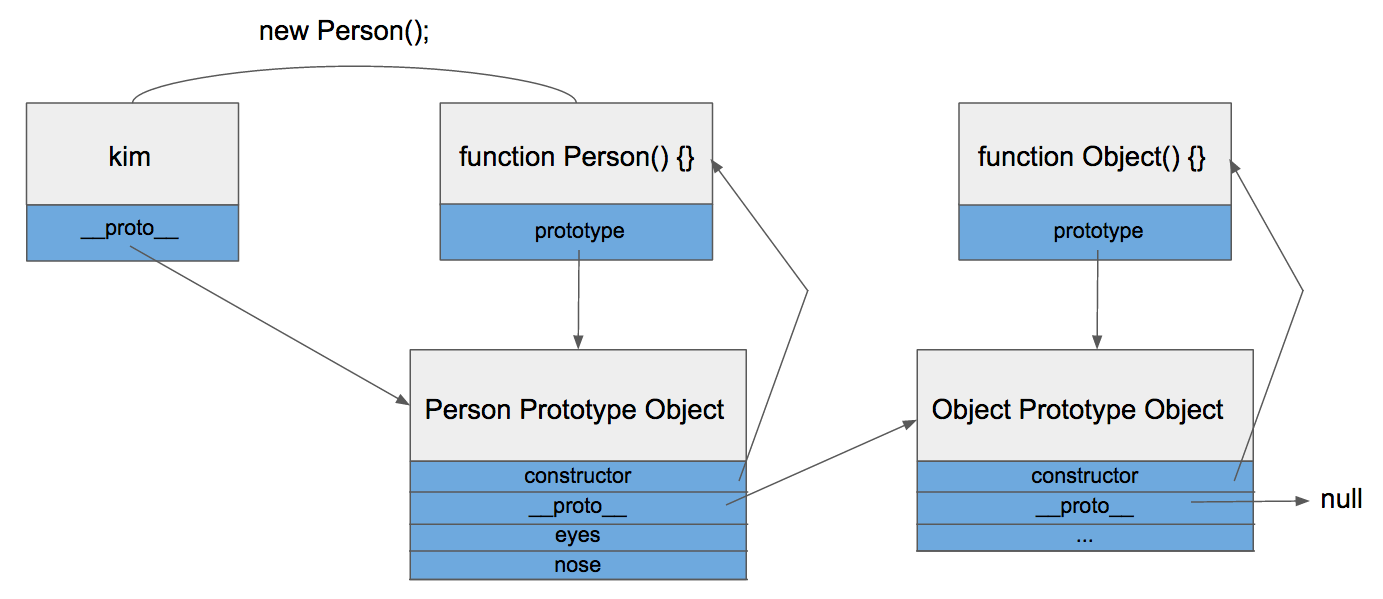
kim객체가 eyes를 직접 가지고 있지 않기 때문에 eyes 속성을 찾을 때 까지 상위 프로토타입을 탐색합니다. 최상위인 Object의 Prototype Object까지 도달했는데도 못찾았을 경우 undefined를 리턴합니다. 이렇게 __proto__속성을 통해 상위 프로토타입과 연결되어있는 형태를 프로토타입 체인(Chain)이라고 합니다.
프로토타입 체인, 최상위는 Object
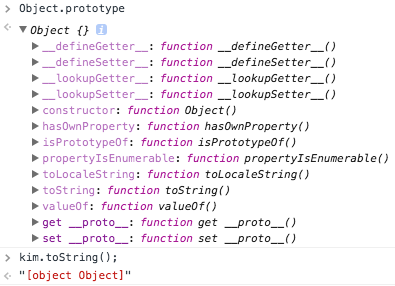
이런 프로토타입 체인 구조 때문에 모든 객체는 Object의 자식이라고 불리고, Object Prototype Object에 있는 모든 속성을 사용할 수 있습니다. 한 가지 예를 들면 toString함수가 있겠습니다.
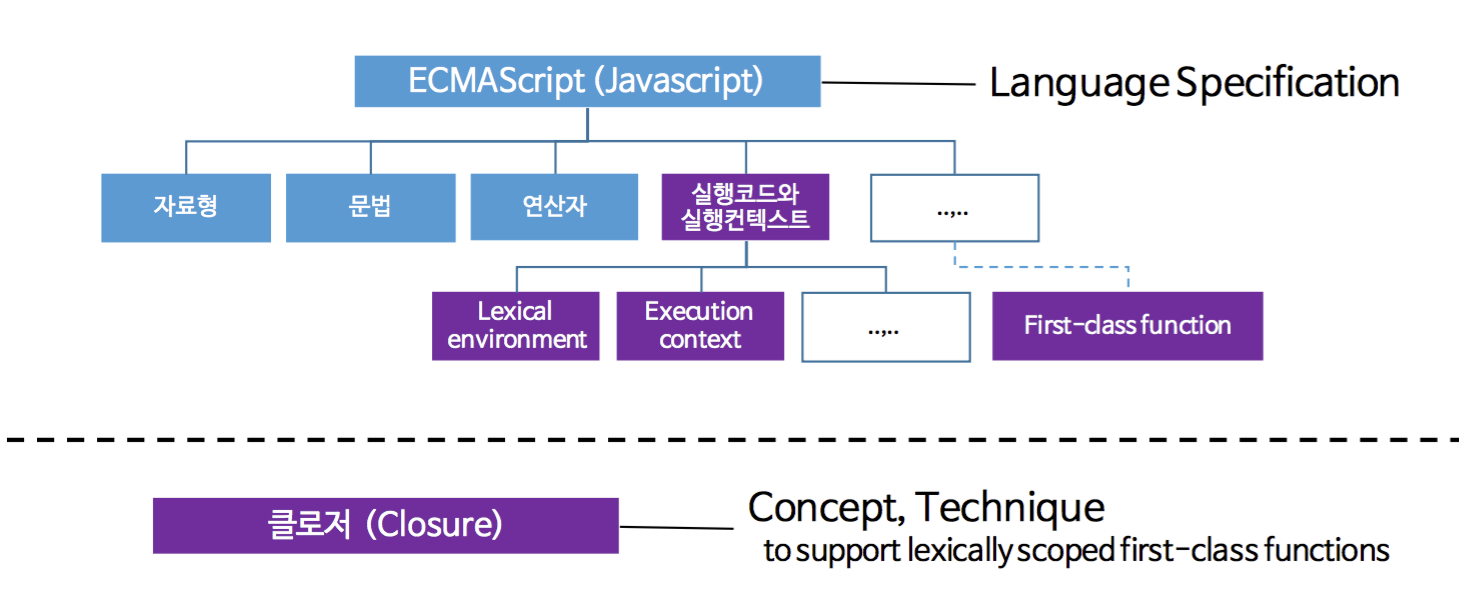
기본적으로 자바스크립트는 ECMAScript 언어 명세를 따르고 있다. 이 명세 8장의 실행코드와 실행컨텍스트 부분에서 스코프에 관한 동작 방식을 확인할 수 있으며, 또 중요한 개념인 1급 객체로서의 함수는 그 특징을 명세의 전반적인 부분에서 나타내고 있다. 그리고, 클로저(Closure)에 대한 정의는 없다. 클로저는 자바스크립트가 채용하고 있는 기술적 기반 혹은 컨셉으로, 자바스크립트는 클로저를 이용하여 스코프적 특징과 일급 객체로서의 함수에 대한 명세를 구현한 것이다.
스코프
김춘수 시인의 "꽃"이라는 시를 보면, 어떤 하나의 몸짓은 이름을 통해 의미를 부여 받고 꽃이 된다.
프로그래밍도 마찬가지로 변수나 함수에 이름을 부여하여 의미를 갖도록 한다. 만약 이름이 없다면, 변수나 함수는 다만 그저 하나의 메모리 주소에 지나지 않는다. 그래서 프로그램은 "이름:값"의 대응표를 만들어 사용한다. 이 대응표의 이름을 가지고 코드를 보다 쉽게 이해하고, 또 이름을 통해 값을 저장하고, 다시 가져와 수정한다.
초기 프로그래밍 언어는 이 대응표를 프로그램 전체에서 하나로 관리했는데, 여기에는 이름 충돌의 문제가 있었다. 그래서 충돌을 피하기 위해, 각 언어마다 "스코프"라는 규칙을 만들어 정의하였다. 그렇게 스코프 규칙은 언어의 명세(Specification)가 되었다.
자바스크립트도 마찬가지로 자신의 스코프 규칙이 있다.
자바스크립트(ES6)는 함수 레벨과 블록 레벨의 렉시컬 스코프규칙을 따른다.
스코프 레벨
자바스크립트는 전통적으로 함수 레벨 스코프를 지원해왔고, 얼마 전까지만 해도 블록 레벨 스코프는 지원하지 않았다. 하지만 가장 최신 명세인 ES6(ECMAScript 6)부터 블록 레벨 스코프를 지원하기 시작했다.
함수 레벨 스코프
자바스크립트에서 var키워드로 선언된 변수나, 함수 선언식으로 만들어진 함수는 함수 레벨 스코프를 갖는다. 즉, 함수 내부 전체에서 유효한 식별자가 된다.
아래 코드는 아무런 문제없이 blue를 출력한다.
functionfoo() {
if (true) {
var color = 'blue';
}
console.log(color); // blue
}
foo();
만약 var color가 블록 레벨 스코프였다면, color는 if문이 끝날 때 파괴되고 console.log에서 잘못된 참조로 에러가 발생할 것이다. 그렇지만 color는 함수 레벨의 스코프이기 때문에 foo 함수 내부 어디에서든 에러 발생 없이 참조할 수 있다.
블록 레벨 스코프
ES6의 let, const키워드는 블록 레벨 스코프 변수를 만들어 준다.
functionfoo() {
if(true) {
let color = 'blue';
console.log(color); // blue
}
console.log(color); // ReferenceError: color is not defined
}
foo();
let color를 if블록 내부에서 선언하였다. 때문에 if블록 내부에서 참조할 수 있으며, 그 밖의 영역에서 잘못된 참조로 에러가 발생한다.
var vs let, const
ES6가 표준화되면서, 블록 레벨과 함수 레벨을 모두 지원하게 되었다. "You don't know JS" 시리즈의 저자인 Kyle Simpson은 var, let, const가 서로 다르기에 필요한 상황에 알맞게 사용할 줄 알아야 한다고 설명하고 있다.
그렇지만 요즈음 ES6 코드 대부분은 var를 사용하지 않는다. var는 let과 const로 모두 대체가 가능하고, var자체가 함수 레벨의 스코프를 가지기 때문에 블록 레벨 스코프보다 더 많은 혼란을 야기하기 때문이다.
렉시컬 스코프
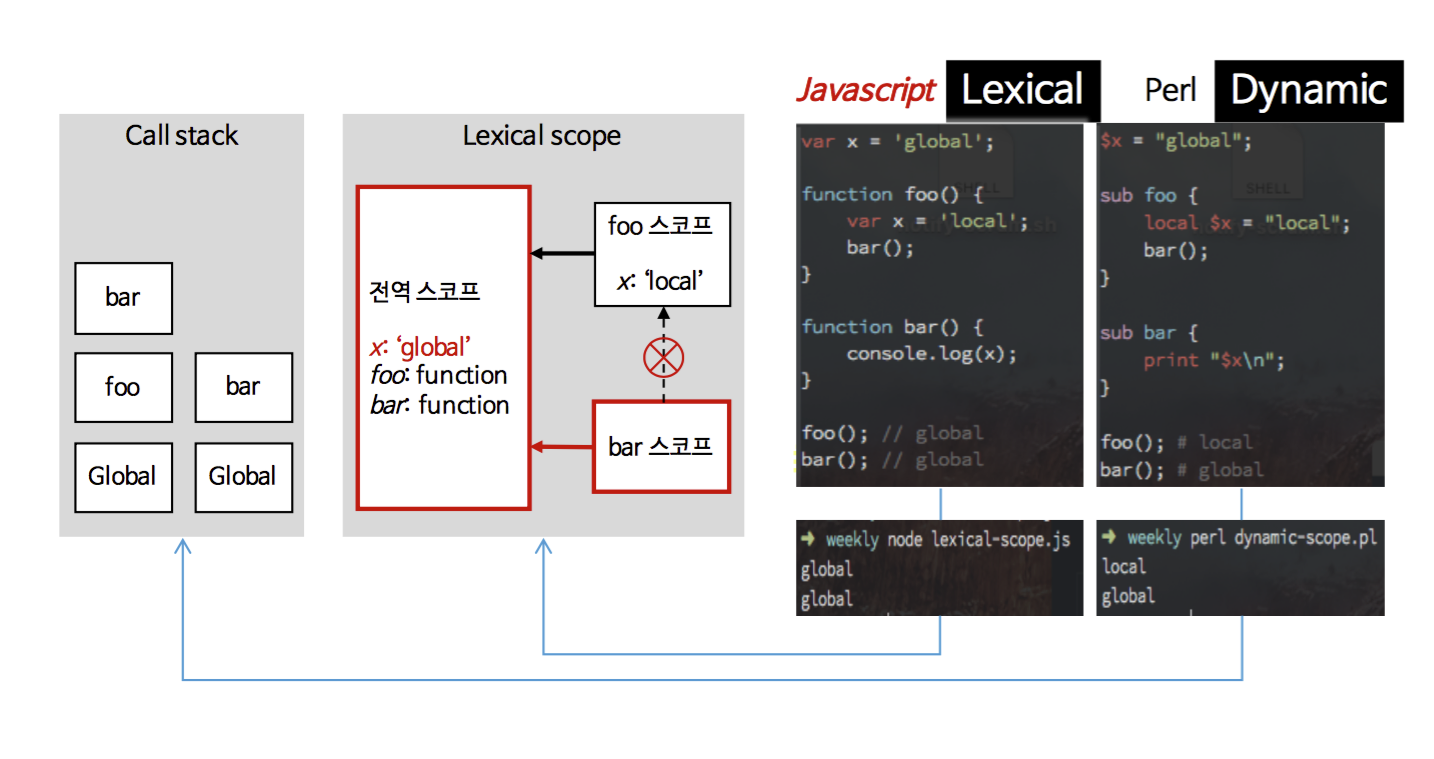
렉시컬 스코프(Lexical scope)는 보통 동적 스코프(Dynamic scope)와 많이 비교한다.
위키피디아를 보면 동적 스코프와 렉시컬 스코프를 다음과 같이 정의하고 있다.
동적 스코프
The name resolution depends upon the program state when the name is encountered which is determined by the execution context or calling context.
렉시컬 스코프 (정적 스코프(Static scope) 또는 수사적 스코프(Rhetorical scope))
The name resolution depends on the location in the source code and the lexical context, which is defined by where the named variable or function is defined.
동적 스코프는 프로그램의 런타임 도중의 실행 컨텍스트나 호출 컨텍스트에 의해 결정되고, 렉시컬 스코프에서는 소스코드가 작성된 그 문맥에서 결정된다. 현대 프로그래밍에서 대부분의 언어들은 렉시컬 스코프 규칙을 따르고 있다.
동적 스코프와 렉시컬 스코프는 자바스크립트와 Perl을 비교하여 확인할 수 있다. 아래는 자바스크립트와 Perl로 같은 코드를 작성하였을 때 나오는 결과이다.
자바스크립트는 렉시컬 스코프 규칙을 통해 global, global을 출력하였으며, Perl은 동적 스코프 규칙을 통해 local, global을 출력하였다. (참고로 Perl에서 local대신 my키워드를 사용하면 변수의 유효범위를 제한하여, 자바스크립트와 같은 결과를 얻을 수 있다.)
렉시컬 스코프 규칙을 따르는 자바스크립트의 함수는 호출 스택과 관계없이 각각의 (this를 제외한)대응표를 소스코드 기준으로 정의하고, 런타임에 그 대응표를 변경시키지 않는다. (사실 런타임에 렉시컬 스코프를 수정할 수 있는 방법들(eval, with)이 있지만, 권장하지 않는다.)
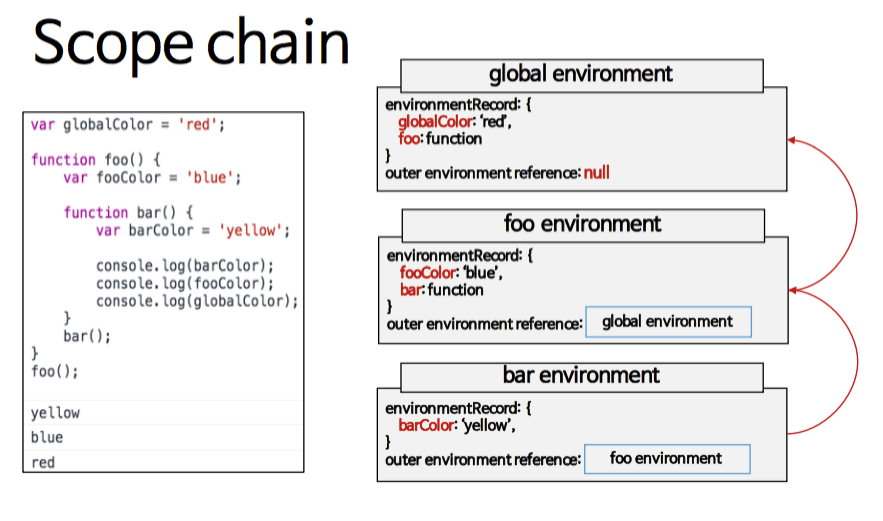
중첩 스코프(스코프 체인 또는 스코프 버블)
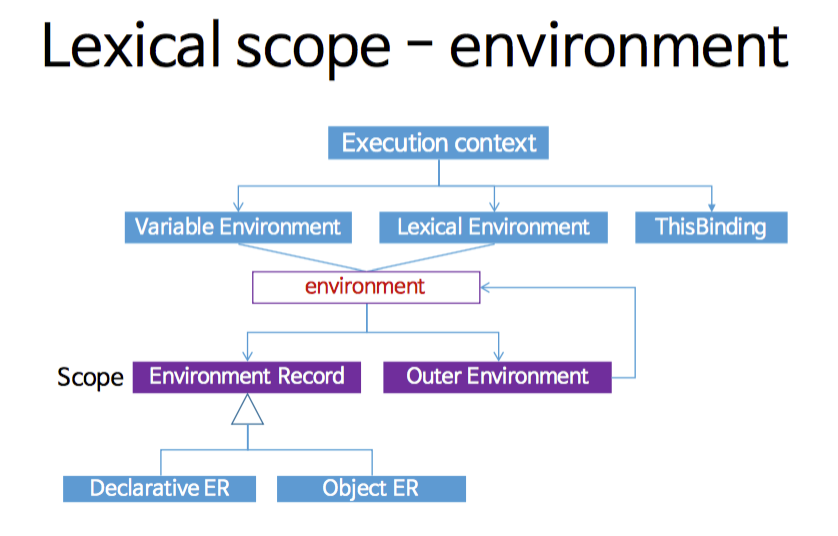
우리가 말하는 이 자바스크립트의 스코프는 ECMAScript 언어 명세에서 렉시컬 환경(Lexical environment)과 환경 레코드(Environment Record)라는 개념으로 정의되었다.
6.2.5 The Lexical Environment and Environment Record Specification Types
The Lexical Environment and Environment Record types are used to explain the behaviour of name resolution in nested functions and blocks. These types and the operations upon them are defined in 8.1.
간단하게 그림으로 표현해보면 아래와 같은 형태로 볼 수 있다.
앞에서 설명한 "이름:값의 대응표"가 환경 레코드와 같다고 볼 수 있고, 렉시컬 환경은 이 환경 레코드와 상위 렉시켤 환경(Outer lexical environment)에 대한 참조로 이루어진다.
현재-렉시컬 환경의 대응표(환경 레코드)에서 변수를 찾아보고, 없다면 바깥 렉시컬 환경을 참조하여 찾아보는 식으로 중첩 스코프가 가능해진다. 이 중첩 스코프 탐색은 해당하는 이름을 찾거나 바깥 렉시컬 환경 참조가 null이 될 때 탐색을 멈춘다.
참고: ECMA-262 Edition3를 보면 자바스크립트의 스코프적 특징은 Scope chain(=list)과 Activation Object등의 개념으로 설명하였다. 그리고 이 설명들이 전반적으로 널리 알려졌지만, 이 다음 명세인 ECMA262 Edition5부터는 Lexical Environment와 Environment Record의 개념으로 스코프를 설명하고 있다.
호이스팅
전통적인 자바스크립트 스코프의 특징은 다음 두 가지라는 것을 알았다.
렉시컬 스코프
함수 레벨 스코프 (+ 블록 레벨 스코프-ES6)
그럼 아래와 같은 상황에선 어떤 값이 출력될까?
functionfoo() {
a = 2;
var a;
console.log(a);
}
foo();
2가 정상적(?)으로 출력된다. 그럼 다음은 어떨지 생각해보자.
functionfoo() {
console.log(a);
var a = 2;
}
foo();
이번에는 undefined가 출력된다. 조금 터무니없다고 느낄 수 있지만, 알고보면 그렇게까지 터무니없는 것은 아니다.
자바스크립트 엔진은 코드를 인터프리팅 하기 전에 그 코드를 먼저 컴파일한다. var a = 2;를 하나의 구문으로 생각할 수도 있지만, 자바스크립트는 다음 두 개의 구문으로 분리하여 본다.
var a;
a = 2;
변수 선언(생성) 단계와 초기화 단계를 나누고, 선언 단계에서는 그 선언이 소스코드의 어디에 위치하든 해당 스코프의 컴파일단계에서 처리해버리는 것이다. (언어 스펙상으로 변수는 렉시컬 환경이 인스턴스화되고 초기화될 때 생성된다고 한다.) 때문에 이런 선언단계가 스코프의 꼭대기로 호이스팅("끌어올림")되는 작업이라고 볼 수 있는 것이다.
참고: 블록스코프인 let도 호이스팅이 된다. 그렇지만 선언 전에 참조할 경우 undefined를 반환하지 않고 ReferenceError를 발생시키는 특징이 있다.
Temporal dead zone and errors with let
In ECMAScript 2015, let will hoist the variable to the top of the block. However, referencing the variable in the block before the variable declaration results in a ReferenceError. The variable is in a "temporal dead zone" from the start of the block until the declaration is processed.
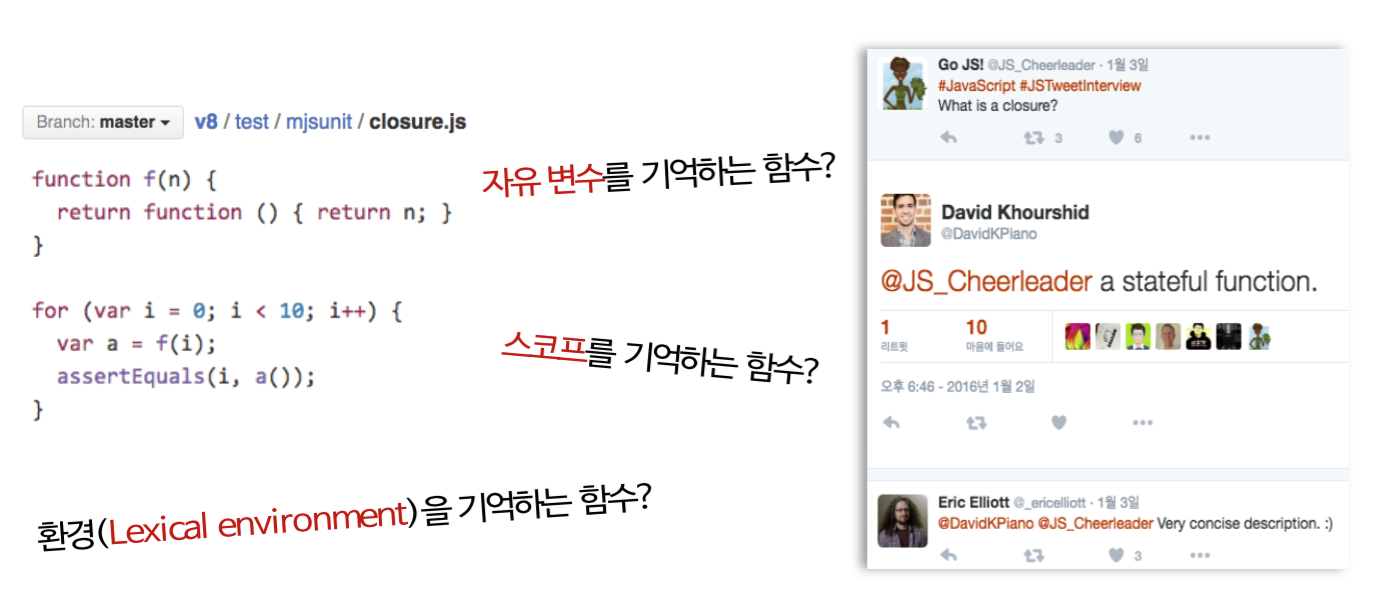
클로저(Closure)
자바스크립트에서 (언어 명세에 없는) 클로저에 대한 정의는 꽤 많은 사람들이 가장 궁금해하는 부분이다.
아래는 실제 v8엔진의 클로저 테스트코드와 사람들이 말하는 클로저의 의미들이다.
종합해보면 함수가 무언가를 기억하고 그것을 다시 사용한다는 것을 알 수 있지만, 여전히 모호하게 느껴진다. 이 모호함을 없애기 위해 클로저의 탄생부터 알아봐야 할 것 같다.
위 정의를 토대로, 클로저를 현대 프로그래밍에서 다음과 같이 해석하여 정의할 수 있을것 같다.
클로저 =
함수 + 함수를 둘러싼 환경(Lexical environment)
함수를 둘러싼 환경이라는 것이 바로 앞에서 설명했던 렉시컬 스코프이다. 함수를 만들고 그 함수 내부의 코드가 탐색하는 스코프를 함수 생성 당시의 렉시컬 스코프로 고정하면 바로 클로저가 되는 것이다.
이제 이 클로저가 자바스크립트에 어떻게 녹아 들어갔는지 살펴보도록 하자.
자바스크립트의 클로저
자바스크립트에서 클로저는 함수가 생성되는 시점에 생성된다. = 함수가 생성될 때 그 함수의 렉시컬 환경을 포섭(closure)하여 실행될 때 이용한다.
따라서 개념적으로 자바스크립트의 모든 함수는 클로저이지만, 실제로 우리는 자바스크립트의 모든 함수를 전부 클로저라고 부르지는 않는다.
다음 예시들을 통해서 클로저를 조금 더 정확하게 파악할 수 있다.
functionfoo() {
var color = 'blue';
functionbar() {
console.log(color);
}
bar();
}
foo();
bar함수는 우리가 부르는 클로저일까 아닐까?
일단 bar는 foo안에 속하기 때문에 foo스코프를 외부 스코프(outer lexical environment) 참조로 저장한다. 그리고 bar는 자신의 렉시컬 스코프 체인을 통해 foo의 color를 정확히 참조할 것이다.
그럼 클로저라 볼 수 있지 않을까?
아니다. 우리가 부르는 클로저라고 하기에는 약간 거리가 있다.bar는 foo안에서 정의되고 실행되었을 뿐, foo밖으로 나오지 않았기 때문에 클로저라고 부르지 않는다.
대신, 다음 코드는 우리가 실제로 부르는 클로저를 나타내고 있다.
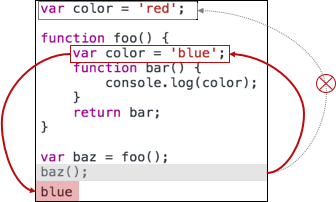
var color = 'red';
functionfoo() {
var color = 'blue'; // 2functionbar() {
console.log(color); // 1
}
return bar;
}
var baz = foo(); // 3
baz(); // 4
bar는 color를 찾아 출력하는 함수로 정의되었다.
그리고 bar는 outer environment 참조로 foo의 environment를 저장하였다.
bar를 global의 baz란 이름으로 데려왔다.
global에서 baz(=bar)를 호출했다.
bar는 자신의 스코프에서 color를 찾는다.
없다. 자신의 outer environment 참조를 찾아간다.
outer environment인 foo의 스코프를 뒤진다. color를 찾았다. 값은 blue이다.
때문에 당연히 blue가 출력된다.
이게 바로 클로저다. 그냥 단순하게 보면 "이 당연하게 왜?"라고 생각할 수 있지만, 조금 더 자세히 따져보도록 하자.
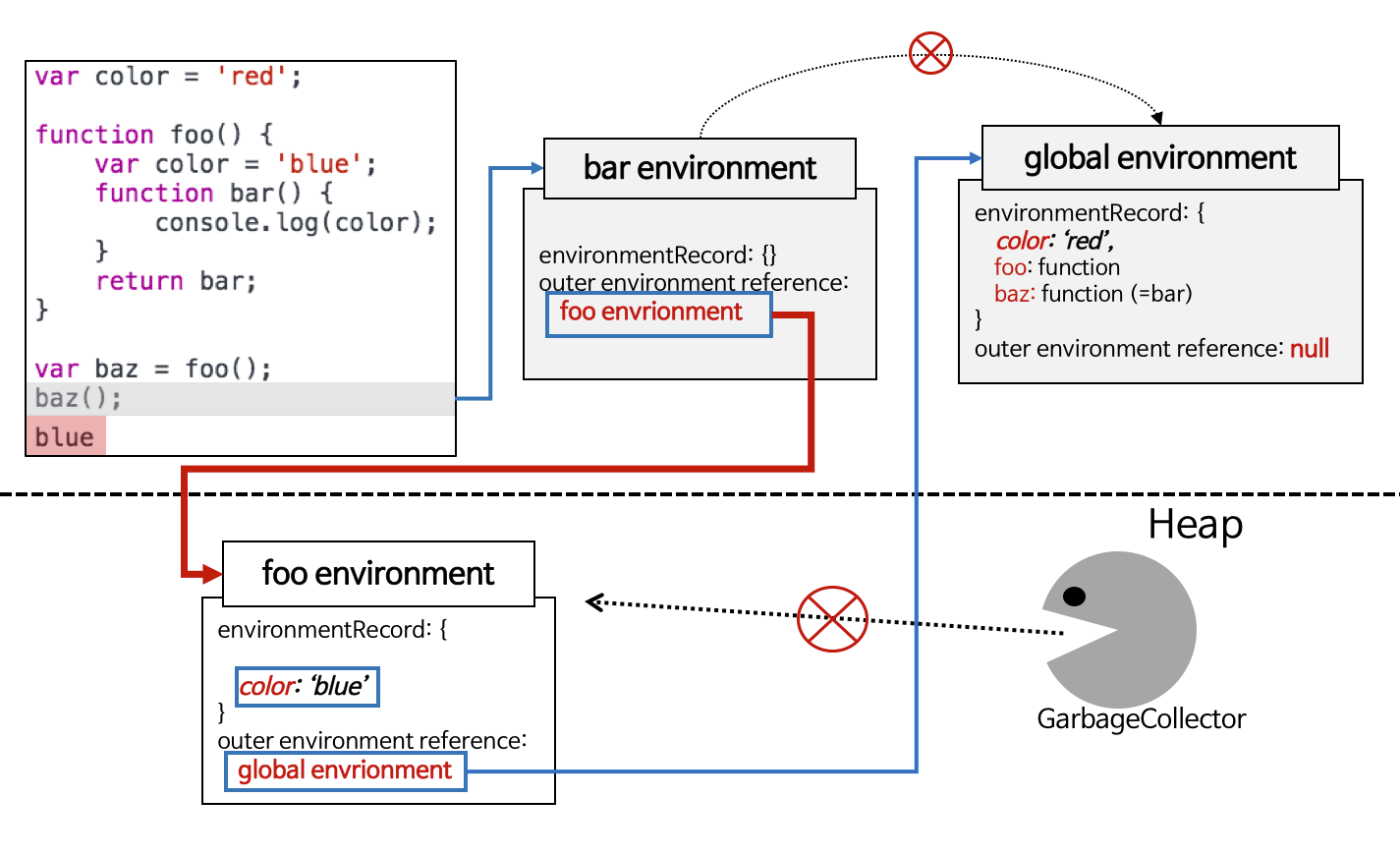
일단 중요한 부분은 2~4번, 그리고 7번이다. bar는 자신이 생성된 렉시컬 스코프에서 벗어나 global에서 baz라는 이름으로 호출이 되었고, 스코프 탐색은 현재 실행 스택과 관련 없는 foo를 거쳐 갔다.baz를 bar로 초기화할 때는 이미 bar의 outer lexical environment를 foo로 결정한 이후이다. 때문에, bar의 생성과 직접적인 관련이 없는 global에서 아무리 호출하더라도 여전히 foo에서 color를 찾는 것이다. 이런 bar(또는 baz)와 같은 함수를 우리는 클로저라고 부른다.
여기에서 다시 한번 강조하지만 JS의 스코프는 렉시컬 스코프, 즉 이름의 범위는 소스코드가 작성된 그 문맥에서 바로 결정되는 것이다.
추가로, foo의 렉시컬환경 인스턴스는 foo();수행이 끝난 이후 GC가 회수해야 하는데 사실을 그렇지 않다. 앞에 설명했듯 bar는 여전히 바깥 렉시컬 환경인 foo의 렉시컬 환경을 계속 참조하고 있고, 이 bar는 baz가 여전히 참조하고 있기 때문이다.(baz(=bar) -> foo)
유명하고 또 유명한 반복문 클로저
functioncount() {
var i;
for (i = 1; i < 10; i += 1) {
setTimeout(functiontimer() {
console.log(i);
}, i*100);
}
}
count();
이 코드는 1, 2, 3, ... 9를 0.1초마다 출력하는 것이 목표였는데, 결과로는 10이 9번 출력되었다. 왜일까?
timer는 클로저로 언제 어디서 어떻게 호출되던지 항상 상위 스코프인 count에게 i를 알려달라고 요청할 것이다. 그리고 timer는 0.1초 후 호출된다. 그런데 첫 0.1초가 지날 동안 이미 i는 10이 되었다. 그리고 timer는 0.1초 주기로 호출될 때마다 항상 count에서 i를 찾는다. 결국, timer는 이미 10이 되어버린 i만 출력하게 된다.
그럼 의도대로 1~9까지 차례대로 출력하고 싶으면 어떻게 해야 할까?
새로운 스코프를 추가하여 반복 시마다 그곳에 각각 따로 값을 저장하는 방식
ES6에서 추가된 블록 스코프를 이용하는 방식
이렇게 두 가지가 있을 것이다.
다음 코드는 원래 의도대로 동작한다.
새로운 스코프를 추가하여 반복 시마다 그곳에 각각 따로 값을 저장하는 방식
functioncount() {
var i;
for (i = 1; i < 10; i += 1) {
(function(countingNumber) {
setTimeout(functiontimer() {
console.log(countingNumber);
}, i * 100);
})(i);
}
}
count();
ES6에서 추가된 블록 스코프를 이용하는 방식
functioncount() {
'use strict';
for (let i = 1; i < 10; i += 1) {
setTimeout(functiontimer() {
console.log(i);
}, i * 100);
}
}
count();
Reference
니시오 히로카즈, 『코딩을 지탱하는 기술』, 김완섭, 비제이퍼블릭(2013)
니콜라스 자카스, 『JavaScript for Web Developers』, 한선용, 인사이트(2013)
ECMAScript에는 이벤트 루프가 없다 단일 호출 스택과 Run-to-Completion 태스크 큐와 이벤트 루프 비동기 API와 try-catch setTimeout(fn, 0) 프라미스(Promise)와 이벤트 루프 마치며 참고 링크
자바스크립트의 큰 특징 중 하나는 '단일 스레드' 기반의 언어라는 점이다. 스레드가 하나라는 말은 곧, 동시에 하나의 작업만을 처리할 수 있다라는 말이다. 하지만 실제로 자바스크립트가 사용되는 환경을 생각해보면 많은 작업이 동시에 처리되고 있는 걸 볼 수 있다. 예를 들면, 웹브라우저는 애니메이션 효과를 보여주면서 마우스 입력을 받아서 처리하고, Node.js기반의 웹서버에서는 동시에 여러 개의 HTTP 요청을 처리하기도 한다. 어떻게 스레드가 하나인데 이런 일이 가능할까? 질문을 바꿔보면 '자바스크립트는 어떻게 동시성(Concurrency)을 지원하는 걸까'?
이때 등장하는 개념이 바로 '이벤트 루프'이다. Node.js를 소개할 때 '이벤트 루프 기반의 비동기 방식으로 Non-Blocking IO를 지원하고..' 와 같은 문구를 본 적이 있을 것이다. 즉, 자바스크립트는 이벤트 루프를 이용해서 비동기 방식으로 동시성을 지원한다. 동기 방식의(Java 같은) 다른 언어를 사용하다가 Node.js 등을 통해 자바스크립트를 처음 접하게 되는 사람들은 이 '이벤트 루프'의 개념이 익숙하지 않아서 애를 먹는다. 뿐만 아니라 자바스크립트를 오랫동안 사용해서 비동기 방식의 프로그래밍에 익숙한 사람들조차 이벤트 루프가 실제로 어떻게 동작하는지에 대해서는 자세히 모르는 경우가 많다.
좀 지난 동영상이지만 최근에 Help, I’m stuck in an event-loop를 우연히 보게 되었는데, 내가 이벤트 루프에 대해 잘못 이해하고 있는 부분들이 많다는 것을 알게 되었다. 그래서 이번 기회에 이벤트 루프에 대해 좀더 자세히 공부해 보았는데, 정리도 할 겸 중요한 사실 몇 가지를 공유해볼까 한다.
ECMAScript에는 이벤트 루프가 없다
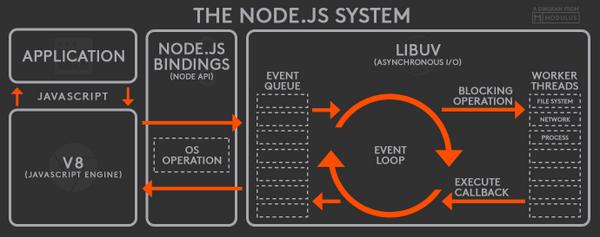
웬만큼 두꺼운 자바스크립트 관련 서적들을 뒤져봐도 이벤트 루프에 대한 설명은 의외로 쉽게 찾아보기가 힘들다. 그 이유는 아마, 실제로 ECMAScript 스펙에 이벤트 루프에 대한 내용이 없기 때문일 것이다. 좀더 구체적으로 표현하면 'ECMAScript 에는 동시성이나 비동기와 관련된 언급이 없다'고 할 수 있겠다(사실 ES6부터는 조금 달라졌지만, 나중에 좀더 설명하겠다). 실제로 V8과 같은 자바스크립트 엔진은 단일 호출 스택(Call Stack)을 사용하며, 요청이 들어올 때마다 해당 요청을 순차적으로 호출 스택에 담아 처리할 뿐이다. 그렇다면 비동기 요청은 어떻게 이루어지며, 동시성에 대한 처리는 누가 하는 걸까? 바로 이 자바스크립트 엔진을 구동하는 환경, 즉 브라우저나 Node.js가 담당한다. 먼저 브라우저 환경을 간단하게 그림으로 표현하면 다음과 같다.
위 그림에서 볼 수 있듯이 실제로 우리가 비동기 호출을 위해 사용하는 setTimeout이나 XMLHttpRequest와 같은 함수들은 자바스크립트 엔진이 아닌 Web API 영역에 따로 정의되어 있다. 또한 이벤트 루프와 태스크 큐와 같은 장치도 자바스크립트 엔진 외부에 구현되어 있는 것을 볼 수 있다. 다음은 Node.js 환경이다.
이 그림에서도 브라우저의 환경과 비슷한 구조를 볼 수 있다. 잘 알려진 대로 Node.js는 비동기 IO를 지원하기 위해 libuv 라이브러리를 사용하며, 이 libuv가 이벤트 루프를 제공한다. 자바스크립트 엔진은 비동기 작업을 위해 Node.js의 API를 호출하며, 이때 넘겨진 콜백은 libuv의 이벤트 루프를 통해 스케쥴되고 실행된다.
이제 어느 정도 감이 잡힐 것이다. 각각에 대해 좀더 자세히 알아보기 전에 한가지만 확실히 짚고 넘어가자. 자바스크립트가 '단일 스레드' 기반의 언어라는 말은 '자바스크립트 엔진이 단일 호출 스택을 사용한다'는 관점에서만 사실이다. 실제 자바스크립트가 구동되는 환경(브라우저, Node.js등)에서는 주로 여러 개의 스레드가 사용되며, 이러한 구동 환경이 단일 호출 스택을 사용하는 자바 스크립트 엔진과 상호 연동하기 위해 사용하는 장치가 바로 '이벤트 루프'인 것이다.
단일 호출 스택과 Run-to-Completion
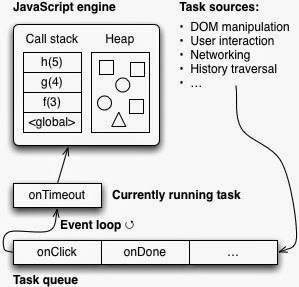
이벤트 루프에 대해 좀더 알아보기 전에, 먼저 자바스크립트 언어의 특징을 하나 살펴보자. 자바스크립트의 함수가 실행되는 방식을 보통 "Run to Completion" 이라고 말한다. 이는 하나의 함수가 실행되면 이 함수의 실행이 끝날 때까지는 다른 어떤 작업도 중간에 끼어들지 못한다는 의미이다. 앞서 말했듯이 자바스크립트 엔진은 하나의 호출 스택을 사용하며, 현재 스택에 쌓여있는 모든 함수들이 실행을 마치고 스택에서 제거되기 전까지는 다른 어떠한 함수도 실행될 수 없다. 다음의 예제를 보자.
자바스크립트를 경험해본 사람이라면, 아무리 delay 함수가 10ms 보다 오래 걸린다고 해도 'baz!'가 'foo!' 보다 먼저 콘솔에 찍히는 일은 없을 거라는 것을 알 것이다. 즉, foo 내부에서 bar를 호출하기 전에 10ms이 지났다고 해도 baz가 먼저 호출되지는 않는다는 말이다. 그러므로 위의 예제를 실행하면 콘솔에는 'bar!' -> 'foo!' -> 'baz!'의 순서로 찍히게 된다. 위의 코드가 전역 환경에서 실행된다고 가정하고 코드내 주석으로 숫자가 적힌 각 시점의 호출 스택을 그림으로 그려보면 다음과 같을 것이다.
(전역 환경에서 실행되는 코드는 한 단위의 코드블록으로써 가상의 익명함수로 감싸져 있다고 생각하는 것이 좋다. 따라서 위의 코드의 첫 줄이 실행될 때에 호출 스택의 맨 아래에 익명 함수가 하나 추가되며, 마지막 라인까지 실행되고 나서야 스택에서 제거된다.)
setTimeout 함수는 브라우저에게 타이머 이벤트를 요청한 후에 바로 스택에서 제거된다. 그 후에 foo 함수가 스택에 추가되고, foo 함수가 내부적으로 실행하는 함수들이 차례로 스택에 추가되었다가 제거된다. 마지막으로 foo 함수가 실행을 마치면서 호출 스택이 비워지게 되고, 그 이후에 baz 함수가 스택에 추가되어 콘솔에 'baz!'가 찍히게 된다.
(결과적으로 baz는 10ms보다 더 늦게 실행되게 될 것이다. 즉, 자바스크립트의 타이머는 정확한 타이밍을 보장해주지 않는데, 이와 관련해서 잘 설명된 John Resig의 글이 있으니 관심 있으신 분들은 클릭!)
태스크 큐와 이벤트 루프
여기서 하나의 궁금증이 생긴다. setTimeout 함수를 통해 넘긴 baz 함수는 어떻게 foo 함수가 끝나자 마자 실행될 수 있을까? 어디서 대기하고 있다가 누구를 통해 실행될까? 바로 이 역할을 하는 것이 태스크 큐와 이벤트 루프이다. 태스크 큐는 말 그대로 콜백 함수들이 대기하는 큐(FIFO) 형태의 배열이라 할 수 있고, 이벤트 루프는 호출 스택이 비워질 때마다 큐에서 콜백 함수를 꺼내와서 실행하는 역할을 해 준다.
앞선 예제를 살펴보자. 코드가 처음 실행되면 이 코드는 '현재 실행중인 태스크'가 된다. 코드를 실행하는 도중 10ms이 지나면 브라우저의 타이머가 baz를 바로 실행하지 않고 태스크 큐에 추가한다. 이벤트 루프는 '현재 실행중인 태스크'가 종료되자 마자 태스크 큐에서 대기중인 첫 번째 태스크를 실행할 것이다. foo가 실행을 마치고 호출 스택이 비워지면 현재 실행중인 태스크는 종료되며, 그 때 이벤트 루프가 태스크 큐에 대기중인 첫 번째 태스크인 baz를 실행해서 호출 스택에 추가한다.
MDN의 이벤트 루프 설명을 보면 왜 '루프'라는 이름이 붙었는지를 아주 간단한 가상코드로 설명하고 있다.
위 코드의 waitForMessage() 메소드는 현재 실행중인 태스크가 없을 때 다음 태스크가 큐에 추가될 때까지 대기하는 역할을 한다. 이런 식으로 이벤트 루프는 '현재 실행중인 태스크가 없는지'와 '태스크 큐에 태스크가 있는지'를 반복적으로 확인하는 것이다. 간단하게 정리하면 다음과 같을 것이다.
모든 비동기 API들은 작업이 완료되면 콜백 함수를 태스크 큐에 추가한다.
이벤트 루프는 '현재 실행중인 태스크가 없을 때'(주로 호출 스택이 비워졌을 때) 태스크 큐의 첫 번째 태스크를 꺼내와 실행한다.
이 코드를 실행하면 아무런 지연 없이 setTimeout 함수가 세 번 호출된 이후에 실행을 마치고 호출 스택이 비워질 것이다. 그리고 10ms가 지나는 순간 foo, bar, baz 함수가 순차적으로 태스크 큐에 추가된다. 이벤트 루프는 foo 함수가 태스크 큐에 들어오자 마자, 호출 스택이 비어있으므로 바로 foo를 실행해서 호출 스택에 추가한다. foo 함수의 실행이 끝나고 호출 스택이 비워지면 이벤트 루프가 다시 큐에서 다음 콜백인 bar를 가져와 실행한다. bar의 실행이 끝나면 마찬가지로 큐에 남아있는 baz를 큐에서 가져와 실행한다. 그리고 baz까지 실행이 모두 완료되면 현재 진행중인 태스크도 없고 태스크 큐도 비어있기 때문에, 이벤트 루프는 새로운 태스크가 태스크 큐에 추가될 때까지 대기하게 된다.
(글의 서두에 언급했던 영상을 보면 발표자가 직접 만든 인터랙션 환경을 사용해 이 과정을 정말 이해하기 쉽게 잘 설명하고 있다. 안보신 분들은 꼭 확인해 보길 바란다.)
비동기 API와 try-catch
setTimeout 뿐만 아니라 브라우저의 다른 비동기 함수들(addEventListener, XMLHttpRequest… )이나 Node.js의 IO 관련 함수들 등 모든 비동기 방식의 API들은 이벤트 루프를 통해 콜백 함수를 실행한다. 자, 그러면 다음과 아래와 같은 코드가 왜 에러를 잡아낼 수 없는지 이제는 확실히 알 수 있을 것이다.
$('.btn').click(function() { // (A)try {
$.getJSON('/api/members', function (res) { // (B)// 에러 발생 코드
});
} catch (e) {
console.log('Error : ' + e.message);
}
});
위의 코드에서 버튼이 클릭되어 콜백 A가 실행될 때 $.getJSON 함수는 브라우저의 XMLHttpRequest API를 통해 서버로 비동기 요청을 보낸 후에 바로 실행을 마치고 호출 스택에서 제거된다. 이후에 서버에서 응답을 받은 브라우저는 콜백 B를 태스크 큐에 추가 하고 B는 이벤트 루프에 의해 실행되어 호출 스택에 추가된다. 하지만 이때 A는 이미 호출 스택에서 비워진 상태이기 때문에 호출 스택에는 B만 존재할 뿐이다. 즉 B는 A가 실행될 때와는 전혀 다른 독립적인 컨텍스트에서 실행이 되며, 그렇기 A 내부의 try-catch 문에 영향을 받지 않는다.
(마찬가지 이유로 에러가 발생했을 때 브라우저의 개발자 도구에서 호출 스택을 들여다봐도 B만 덩그라니 놓여있는 것을 볼 수 있을 것이다.)
(이런 이유로 Node.js의 비동기 API들은 중첩된 콜백 호출에 대한 에러 처리를 위해 '첫 번째 인수는 에러 콜백 함수' 라는 컨벤션을 따르고 있다)
이를 해결하기 위해서는 콜백 B의 내부에서 try-catch를 실행해야 한다. (물론, 이렇게 해도 네트워크 에러나 서버 에러는 잡을 수 없다. 이를 위해서는 에러 콜백을 따로 제공해야 한다.)
$('.btn').click(function() { // (A)
$.getJSON('/api/members', function (res) { // (B)try {
// 에러 발생 코드
} catch (e) {
console.log('Error : ' + e.message);
}
});
});
setTimeout(fn, 0)
프론트엔드 환경의 자바스크립트 코드를 보다 보면 setTimeout(fn, 0)와 같은 코드를 종종 보게 된다. 관용적으로 쓰이는 코드이지만, 사실 처음 보는 사람에게는 직관적으로 이해하기 힘든 코드일 것이다. 0초 이후에 실행을 한다는 건 실제로 그냥 실행하는 것과 다를 게 없으니 말이다. 하지만 실제로 이 코드는 그냥 fn을 실행하는 것과는 상당히 다른 결과를 가져온다. 위의 예제에서도 보았겠지만 setTimeout 함수는 콜백 함수를 바로 실행하지 않고 (호출 스택이 아닌)태스크 큐에 추가한다. 그렇기 때문에 아래의 코드는 콘솔에 B -> A 순서로 출력하게 될 것이다.
프론트엔드 환경에서는 렌더링 엔진과 관련해서 이런 코드가 특히 요긴하게 쓰일 때가 있다. 브라우저 환경에서는 자바스크립트 엔진뿐만 아니라 다른 여러 가지 프로세스가 함께 구동되고 있다. 렌더링 엔진도 그 중의 일부이며, 이 렌더링 엔진의 태스크는 대부분의 브라우저에서 자바스크립트 엔진과 동일한 단일 태스크 큐를 통해 관리된다. 이로 인해 가끔 예상치 못한 문제가 생길 경우가 있는데, 다음의 코드를 살펴보자.
longTakingProcess가 너무 오래 걸리는 작업이기 때문에 그 전에 showWaitingMessage를 호출해서 로딩 메시지('로딩중…'과 같은)를 보여주려고 한다. 하지만 실제로 이 코드를 실행해 보면 화면에 로딩 메시지가 표시되는 일은 없을 것이다. 이유는 showWaitingMessage 함수의 실행이 끝나고 렌더링 엔진이 렌더링 요청을 보내도 해당 요청은 태스크 큐에서 이미 실행중인 태스크가 끝나기를 기다리고 있기 때문이다. 실행중인 태스크가 끝나는 시점은 호출 스택이 비워지는 시점인데, 그 때는 이미 showResult 까지 실행이 끝나 있을 것이고, 결국 렌더링이 진행되는 시점에는 hideWaitingMessgae로 인해 로딩 메시지가 숨겨진 상태일 것이다. 이를 해결하기 위해서 다음처럼 setTimeout를 사용할 수 있다.
이 경우에는 longTakingProcess가 바로 실행되지 않고 태스크 큐에 추가될 것이다. 하지만 showWaitingMessage로 인해 태스크 큐에는 렌더링 요청이 먼저 추가되기 때문에 longTakingProcess는 그 다음 순서로 태스크 큐에 추가될 것이다. 이제 이벤트 루프는 태스크 큐에 있는 렌더링 요청을 먼저 처리하게 되고 로딩 메시지가 먼저 화면에 보여지게 된다.
꼭 렌더링 관련이 아니라도, 실행이 너무 오래 걸리는 코드를 setTimeout을 사용하여 적절하게 다른 태스크로 나누어 주면 전체 어플리케이션이 멈추거나 스크립트가 너무 느리다며 경고창이 뜨는 상황을 방지할 수도 있을 것이다.
한가지 짚고 넘어갈 사실은 '0' 이라는 숫자가 실제로 '즉시'를 의미하지 않는다는 점이다. 브라우저는 내부적으로 타이머의 최소단위(Tick)를 정하여 관리하기 때문에 실제로는 그 최소단위만큼 지난 후에 태스크 큐에 추가되게 된다. 그리고 이 최소단위는 브라우저별로 조금씩 다른데, 예를 들어 크롬 브라우저의 경우 최소단위로 4ms 사용하기 때문에 크롬에서 setTimeout(fn, 0)은 setTimeout(fn, 4)와 동일한 의미를 갖게 될 것이다.
이런 문제를 해결하기 위해 setImmediate라는 API가 제안되었지만, 안타깝게도 표준의 반열에 오르지는 못하고 IE10 이상에만 포함되어 있다. 실제로 이 메소드는 setTimeout 와 같은 최소단위 지연이 없이 바로 태스크 큐에 해당 콜백을 추가한다. EsLint로 유명한 N.C.Zakas도 이 메소드가 표준화 되지 않은 것에 대해 비판하는 글을 올린 적이 있다. 비슷한 효과를 위해 postMessage 나 MessageChanel을 사용하기도 하는데, 관련된 내용은 setImmediate의 폴리필을 구현한 라이브러리 페이지에 잘 정리되어 있다.
(Node.js 에는 이런 용도를 위해 nextTick이라는 함수가 있지만 0.9버전 부터는 약간 다른 개념으로 사용된다. 다음 절에서 좀더 설명하겠다.)
프라미스(Promise)와 이벤트 루프
이런 이벤트 루프의 개념은 실제로 HTML 스펙에 정의되어 있다. 문서에서 이벤트 루프, 태스크 큐의 개념에 대해 잘 정의되어 있는 것을 볼 수 있을 것이다. 그런데 문서 중간에 마이크로 태스크(microtask) 라는 생소한 용어가 보인다. 이런… 이제 겨우 이벤트 루프에 대해 이해한 것 같은데 뭔가 상황이 더 복잡해질 것 같은 불길한 예감이 든다. 마음을 가다듬고, 다음 코드를 살펴보자.
콘솔에 찍히는 순서는 어떻게 될까? 프라미스도 비동기로 실행된다고 할 수 있으니 태스크 큐에 추가돼서 순서대로 A -> B -> C 가 될까? 아니면 프라미스는 setTimeout처럼 최소단위 지연이 없으니 B -> C -> A 일까? 체인 형태로 연속해서 호출된 then() 함수는 어떤 식으로 동작할까? 결론부터 말하자면 정답은 B -> C -> A 인데, 이유는 바로 프라미스가 마이크로 태스크를 사용하기 때문이다. 그럼 마이크로 태스크가 대체 뭘까?
마이크로 태스크는 쉽게 말해 일반 태스크보다 더 높은 우선순위를 갖는 태스크라고 할 수 있다. 즉, 태스크 큐에 대기중인 태스크가 있더라도 마이크로 태스크가 먼저 실행된다. 위의 예제를 통해 좀더 자세히 알아보자. setTimeout() 함수는 콜백 A를 태스크 큐에 추가하고, 프라미스의 then() 메소드는 콜백 B를 태스크 큐가 아닌 별도의 마이크로 태스크 큐에 추가한다. 위의 코드의 실행이 끝나면 태스크 이벤트 루프는 (일반)태스크 큐 대신 마이크로 태스크 큐가 비었는지 먼저 확인하고, 큐에 있는 콜백 B를 실행한다. 콜백 B가 실행되고 나면 두번째 then() 메소드가 콜백 C를 마이크로 태스크 큐에 추가한다. 이벤트 루프는 다시 마이크로 태스크를 확인하고, 큐에 있는 콜백 C를 실행한다. 이후에 마이크로 태스크 큐가 비었음을 확인한 다음 (일반) 태스크 큐에서 콜백 A를 꺼내와 실행한다. (이런 일련의 작업은 HTML 스펙에서 perform a microtask checkpoint 라는 항목에 명시되어 있다.)
잘 와 닿지 않는 분들은 이와 관련해서 인터랙션과 함께 아주 잘 정리된 글이 있으니 꼭 확인해 보길 바란다. 원문 글에서는 브라우저마다 프라미스의 호출 순서가 다른 문제를 지적하고 있는데, 이유는 프라미스가 ECMAScript에 정의되어 있는 반면, 마이크로 태스크는 HTML 스펙이 정의되어 있는데, 둘의 연관관계가 명확하지 않기 때문이다. (ECMAScript에는 ES6부터 프라미스를 위해 잡 큐(Job Queue)라는 항목이 추가되었지만, HTML 스펙의 마이크로 태크스와는 별도의 개념이다.) 하지만 최근에 Living Standard 상태인 HTML 스펙을 보면 자바스크립트의 잡큐를 어떻게 이벤트 루프와 연동하는지에 대한 항목이 포함되어 있다. 또한 현재는 대부분의 브라우저에서 해당 문제가 수정되어 있는 걸 확인할 수 있다.
(프라미스A+ 스펙문서의 Note를 보면 구현 시에 일반(macro) 태스크나 마이크로 태스크 둘 다 사용할 수 있다고 적혀 있다. 실제로 프라미스가 처음 자바스크립트에 도입되는 시점에는 프라미스를 어떤 순서로 실행할 것인가에 대한 논의가 꽤 있었던 것으로 보인다. 하지만 앞서 언급한 것처럼 현재는 프라미스를 마이크로 태스크라고 정의해도 무리가 없을 것 같다.)
휴우. 정리를 하고 다시 봐도 복잡해 보인다. 하지만, 실제로 마이크로 태스크이냐 일반 태스크이냐에 따라 실행되는 타이밍이 달라지기 때문에 둘을 제대로 이해하고 구분해서 사용하는 것은 중요하다. 예를 들어 마이크로 태스크가 계속돼서 실행될 경우 일반 태스크인 UI 렌더링이 지연되는 현상이 발생할 수도 있을 것이다. 관련해서 잘 정리된 스택오버플로우의 답변도 있으니 참고하면 좋을 것 같다.
이전 절에서 살짝 언급했던 Node.js의 nextTick은 기존에는 일반 태스크를 이용해 구현되었지만, 0.9 버전부터 마이크로 태스크를 이용하도록 변경되었다.
마치며
이벤트 루프는 실제로 자바스크립트 언어의 명세보다는 구동 환경과 더 관련된 내용이기 때문에 다른 프로세스들(렌더링, IO 등)과 밀접하게 연관되어 있어 잘 정리된 자료를 찾기가 쉽지만은 않다. 또한 Node.js의 libuv는 HTML 스펙을 완벽히 따르지는 않기 때문에 브라우저 환경의 이벤트 루프와 상세 구현이 조금씩 다르다(심지어 브라우저 별로도 구현이 조금씩 다르다). 또한, 최근에는 ES6에 프라미스와 잡 큐라는 항목이 추가되며 마이크로 태스크의 개념과 혼동되며 이해하기가 한층 더 복잡해졌다. 여기서 끝이 아니다. 사실 이 글에서는 브라우저가 '단일 이벤트 루프'를 사용한다고 가정하고 설명했지만, 웹 워커(Web Worker)는 각각이 독립적인 이벤트 루프를 사용하며(Worker Event Loop라는 이름으로 구분되어 있다), 이와 관련된 내용을 추가한다면 더더욱 복잡해질 것이다. (하아…)
하지만 자바스크립트의 비동기적 특성을 잘 활용하기 위해서는 이벤트 루프를 제대로 이해하는 것이 중요하다. 특히 (이 글에서는 다루지 못했지만) 웹 워커나 Node.js의 클러스터를 사용하는 멀티 스레드 환경에서는 이벤트 루프에 대한 탄탄한 이해가 없다면 예상치 못한 버그 앞에 좌절하게 될 지도 모른다. 사실 개인적으로도 계속 스펙문서를 부분 부분 뒤져가며 글을 작성하느라 완벽하게 이해하고 정리하지는 못한 기분이다. 하지만 이 글이 조금이나마 도움이 되었기를 바라며, 여기서 만족하지 말고 관련 링크들을 짬짬이 살펴 보면서 이벤트 루프에 대해 제대로 이해하는 기회가 되었으면 좋겠다.
JavaScript는 단순한 언어로 여겨져 왔습니다. 그래서 여러 개발자분들이 JavaScript를 배우기도 쉽고 간단히 쓸 수 있다는 편견을 가지고있습니다. 하지만, 최근 JavaScript의 관심이 늘어나면서 JavaScript는 더이상 '쉬운 언어'가 아닌 깊은 이해를 필요로 하는 언어라는 인식이 생기고있습니다. 저는 JavaScript에 대한 깊은 이해를 하기 위해서는 클로저(Closure)에 대해 알아야 되며 이를 알기 위해서는 Scope 개념의이해가 필요하다고 생각됩니다.
JavaScript 프로그래밍에서 유효범위를 잘 알아야 하는 이유가 무엇일까요? 제 생각은 다음과 같습니다.
유효범위란 JavaScript에서뿐만 아니라 모든 프로그래밍 언어 코드의 가장 기본적인 개념의 하나로 반드시 알아야 합니다. 유효범위의 개념을 모르면 관련된 다른 개념 역시 혼란스러울 수 있습니다.
JavaScript의 유효범위에는 다른 언어의 유효범위와는 다릅니다. 다른 프로그래밍 언어에 익숙한 개발자들은 JavaScript만의 유효범위를 이해해야 합니다.
JavaScript의 유효범위 개념은 간단하게 생각한다면 너무나 쉬운 내용이면서도 쉽게 이해하지 못할 함정에 자주 빠지게 합니다. 돌다리도 두들겨보고 건너라는 말이 있듯이 기본 개념부터 튼튼히 하고 넘어가야 합니다.
1. 유효범위(Scope)
Scope를 직역하면 영역, 범위라는 뜻입니다. 하지만 프로그램 언어에서의 유효범위는 어느 범위까지 참조하는지. 즉, 변수와 매개변수(parameter)의 접근성과 생존기간을 뜻합니다. 따라서 유효범위 개념을 잘 알고 있다면 변수와 매개변수의 접근성과 생존기간을 제어할 수 있습니다. 유효범위의 종류는 크게 두 가지가 있습니다. 하나는 전역 유효범위(Global Scope), 또 하나는 지역 유효범위(Local Scope)입니다. 전역 유효범위는 스크립트 전체에서 참조되는 것을 의미하는데, 말 그대로 스크립트 내 어느 곳에서든 참조됩니다. 지역 유효범위는 정의된 함 수 안에서만 참조되는 것을 의미하며, 함수 밖에서는 참조하지 못합니다.
[그림 1] 유효범위 종류
위 그림은 유효범위의 종류에 대해 좀 더 설명하기 위해 첨부했습니다. 위 그림에서 전역변수(전역 유효범위를 가진 변수)는 globalscope이고 지역변수(지역 유효범위를 가진 변수)는 ascopeparam, localscopea, localscopeb, localscopec입니다. 각각의 지역 변수의 유효범위는 acopeparam, localscopea가 함수(Function) A의 중괄호 안의 영역, localscopeb가 함수 B의 중괄호 안의 영역, localscope_c가 함수 C의 중괄호 안의 영역입니다.
1.1 JavaScript 유효범위의 특징
앞서 JavaScript의 유효범위를 알아야 하는 이유에서 언급했듯 JavaScript의 유효범위는 다른 프로그래밍언어와 다른 개념을 갖습니다. JavaScript 유효범위만의 특징을 크게 분류하여 나열하면 다음과 같습니다.
함수 단위의 유효범위
변수명 중복 허용
var 키워드의 생략
렉시컬 특성
위와 같은 특징들을 지금부터 하나씩 살펴보겠습니다.
function scopeTest() {
var a = 0;
if (true) {
var b = 0;
for (var c = 0; c < 5; c++) {
console.log("c=" + c);
}
console.log("c=" + c);
}
console.log("b=" + b);
}
scopeTest();
//실행결과
/*
c = 0
c = 1
c = 2
c = 3
c = 4
c = 5
b = 0
*/
[예제 1] 유효범위 설정단위
위의 코드는 JavaScript의 유효범위 단위가 블록 단위가 아닌 함수 단위로 정의된다는 것을 설명하기 위한 예제 코드입니다. 다른 프로그래밍 언어들은 유효범위의 단위가 블록 단위이기 때문에 위의 코드와 같은 if문, for문 등 구문들이 사용되었을 때 중괄호 밖의 범위에서는 그 안의 변수를 사용할 수 없습니다. 하지만 JavaScript의 유효범위는 함수 단위이기 때문에 예제코드의 변수 a,b,c모두 같은 유효범위를 갖습니다. 그 결과, 실행화면을 보면 알 수 있듯이 구문 밖에서 그 변수를 참조합니다.
var scope = 10;
function scopeExam(){
var scope = 20;
console.log("scope = " +scope);
}
scopeExam();
//실행결과
/*
scope =20
*/
[예제 2] 변수 명 중복
JavaScript는 다른 프로그래밍 언어와는 달리 변수명이 중복되어도 에러가 나지 않습니다. 단, 같은 변수명이 여러 개 있는 변수를 참조할 때 가장 가까운 범위의 변수를 참조합니다. 위의 코드 실행화면을 보면 함수 내에서 scope를 호출했을 때 전역 변수 scope를 참조하는 것이 아니라 같은 함수 내에 있는 지역변수 scope를 참조합니다.
다른 프로그래밍 언어의 경우 변수를 선언할 때 int나 char와 같은 변수 형을 썼지만, JavaScript는 var 키워드를 사용합니다. 또, 다른 프로그래밍 언어의 경우 변수를 선언할 때 변수형을 쓰지 않을 경우 에러가 나지만 JavaScript는 var 키워드가 생략이 가능합니다. 단, var 키워드를 빼먹고 변수를 선언할 경우 전역 변수로 선언됩니다. 위 코드의 실행 결과를 보면 scope라는 변수가 함수 scopeExam 안에서 변수 선언이 이루어졌지만, var 키워드가 생략된 상태로 선언되어 함수 scopeExam2에서 호출을 했을 때도 참조합니다.
function f1(){
var a= 10;
f2();
}
function f2(){
return console.log("호출 실행");
}
f1();
//실행결과
/*
호출실행
*/
function f1(){
var a= 10;
f2();
}
function f2(){
return a;
}
f1();
//실행결과
/*
Uncaught Reference Error
: a is not defined
*/
[예제 4] 렉시컬 특성
렉시컬 특성이란 함수 실행 시 유효범위를 함수 실행 환경이 아닌 함수 정의 환경으로 참조하는 특성입니다. 위의 좌측코드를 봤을 때 함수 f1에서 함수 f2를 호출하면 실행이 됩니다. 함수 f1,f2 모두 전역에서 생성된 함수여서 서로를 참조할 수 있죠. 하지만 우측코드처럼 함수 f1안에서 함수 f2를 호출했다고 해서 f2가 f1안에 들어온 것처럼 f1의 내부 변수 a를 참조할 수 없습니다. 렉시컬 특성으로 인해서 함수 f2가 실행될 때가 아닌 정의 될 때의 환경을 보기 때문에 참조하는 a라는 변수를 찾을 수 없습니다. 그래서 실행결과는 위와 같이 나옵니다. 또 다른 JavaScript의 특징 중에 하나로 호이스팅이라는 개념이 있습니다. 호이스팅에 대해 살펴 보겠습니다.
1.2 호이스팅(Hoisting)
호이스팅이란 무엇일까요? Hoisting이라는 단어를 직역하면 끌어올리기, 들어 올려 나르기라는 뜻입니다. JavaScript에서 호이스팅도 비슷한 의미를 갖고 있습니다. 간단하게 말해서 JavaScript에서의 호이스팅의 의미는 변수 선언문을 끌어올린다는 뜻으로 이해하면 됩니다. 좀 더 이해를 돕기위해 아래의 코드를 준비했습니다.
function hoistingExam(){
console.log("value="+value);
var value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
function hoistingExam(){
var value;
console.log("value="+value);
value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
[예제 5] 호이스팅
위의 코드는 호이스팅을 설명하기 위한 간단한 예제입니다. 좌측 코드를 보시게 되면 함수 hoistingExam안에서 변수 value의 호출이 두 번 일어납니다. 한 번은 변수 선언문 전에 또 한 번은 변수 선언 후에 호출이 되는데, 다른 프로그래밍 언어의 경우에는 선언문 전에 호출됐을 때 에러가 납니다. 하지만 JavaScript의 경우 호이스팅이 됨으로써 오른쪽 코드와 같은 구동이 이루어집니다. 즉, 변수 선언문이 유효범위 안의 제일 상단부로 끌어올려 지게 되고, 선언문이 있던 자리에서 초기화가 이루어지는 결과를 갖는 것입니다. 그 실행결과 첫 번째 호출에서는 초기화가 되지 않은 undefined가, 두 번째 호출에서는 초기화된 값이 나옵니다.
var value=30;
function hoistingExam(){
console.log("value="+value);
var value =10;
console.log("value="+value);
}
hoistingExam();
//실행결과
/*
value= undefined
value= 10
*/
[예제 6] 호이스팅 2
그렇다면 위와 같은 코드에서는 어떤 결과가 나올까요? 다른 프로그래밍 언어에 익숙한 개발자 분들은 변수 value의 첫 호출에서 전역변수가 참조된다고 생각하실 수 있습니다. 하지만 JavaScript의 호이스팅으로 인해서 선언 부가 함수 hoistingExam의 최 상단에서 끌어올려 짐으로써 전역변수가 아닌 지역변수를 참조합니다.
함수의 호이스팅을 이해할 때는 한 가지만 기억하시면 될 것 같습니다. 바로, 여러 가지의 함수 정의 방법 중 ‘함수 선언문 방식만 호이스팅이 가능하다.’라는 점입니다.
// 함수 선언문
hoistingExam();
function hoistingExam(){
var hoisting_val =10;
console.log("hoisting_val ="+hoisting_val);
}
//실행결과
/*
hoisting_val =10
*/
//함수 표현식
hoistingExam2();
var hoistingExam2 = function(){
var hoisting_val =10;
console.log("hoisting_val ="+hoisting_val);
}
//실행결과
/*
hoistingExam2 of object is not a function
*/
//Function 생성자
hoistingExam3();
var hoistingExam3 = new Function("","return console.log('Ya-ho!!');");
//실행결과
/*
hoistingExam3 of object is not a function
*/
[예제 7] 함수 호이스팅
앞서 말하였듯 위의 코드와 실행결과를 보시면 함수 선언문 방식만 호이스팅이 제대로 이루어집니다. 이 결과를 보고 왜 함수 선언문 방식만 호이스팅이 되고 함수 표현 식과 Function생성자를 통해 함수를 정의하는 방법은 호이스팅이 되지 않는지 궁금해하시는 분들도 계실 것 같은데요. 그 이유는 함수 표현 식과 Function생성자를 통한 함수 정의 방법은 변수에 함수를 초기화시키기 때문에(이를 함수변수라고도 합니다) 선언문이 호이스팅이 되어 상단으로 올려진다 하더라도 함수가 아닌 변수로써 인지되기 때문입니다. 위의 코드에서 함수실행 구문이 아닌 변수를 호출하게 되면 변수의 호이스팅과 같은 undefined란 결과가 나옵니다.
1.3 실행 문맥(Execution context)
실행 문맥은 간단하게 말해서 실행 정보입니다. 실행에 필요한 여러 가지 정보들을 담고 있는데 정보란 대부분 함수를 뜻합니다. JavaScript는 일종의 콜 스택(Call Stack)을 갖고 있는데, 이 곳에 실행 문맥이 쌓입니다. 콜 스택의 제일 위에 위치하는 실행 문맥이 현재 실행되고 있는 실행 문맥이 되는 것이죠.
console.log("전역 컨텍스트 입니다");
function Func1(){
console.log("첫 번째 함수입니다.");
};
function Func2(){
Func1();
console.log("두 번째 함수입니다.");
};
Func2();
//실행결과
/*
전역 컨텍스트 입니다
첫 번째 함수 입니다.
두 번째 함수 입니다
*/
[그림 2] 코드실행에 따른 실행문맥 스택
스크립트가 실행이 되면 콜 스택에 전역 컨텍스트가 쌓입니다. 위의 코드에서 함수 Func2의 실행 문구가 나와 함수가 실행이 되면 그 위에 Func2의 실행 컨텍스트가 쌓입니다. Func2가 실행되는 도중 함수 Func1이 실행이 되면서 콜 스택에는 Func2 실행 컨텍스트위에 Func1의 실행컨텍스트가 쌓이죠. 그렇게 Func1이 종료가되고 Func2가 종료가 되면서 차례로 컨텍스트들이 스택에서 빠져나오게됩니다. 마지막으로 스크립트가 종료가 되면 전역 컨텍스트가 빠져나오게 되는 구조입니다.
그렇다면 실행 문맥은 어떤 구조로 이루어져있고 어떤 과정을 통해 생성이 될까요? 지금부터 알아보겠습니다.
1.4 실행 문맥 생성
실행 문맥은 크게 3가지로 이루어져 있습니다.
활성화 객체: 실행에 필요한 여러 가지 정보들을 담을 객체입니다. 여러 가지 정보란 arguments객체와 변수등을 말합니다.
유효범위 정보: 현재 실행 문맥의 유효 범위를 나타냅니다.
this 객체: 현재 실행 문맥을 포함하는 객체 입니다.
[그림 3] 실행문맥 생성
위의 코드를 실행하게 되면 함수abcFunction의 실행 문구에서 위와 같은 실행 문맥이 생깁니다. 실행문맥 생성 순서는 다음과 같습니다.
활성화 객체 생성
arguments객체 생성
유효범위 정보 생성
변수 생성
this객체 바인딩
실행
arguments객체는 함수가 실행될 때 들어오는 매개변수들을 모아놓은 유사 배열 객체입니다. 위의 그림에서 Scope Chain이 유효범위 정보를 담는 일종의 리스트이며 0번지는 전역 변수 객체를 참조합니다. Scope Chain에 대해서는 뒤에 다시 한 번 설명하겠습니다. 변수들은 위의 코드의 지역변수와 매개변수 a,b,c 입니다. 매개변수 a와 b는 실행 문맥 생성단계에서 초기화 값이 들어가지만, c의 경우 생성 후 실행 단계에서 초기화가 되기 때문에 undefined란 값을 가지고 생성됩니다.
2. 유효범위 체인(Scope Chain)
유효범위 체인을 간단하게 설명하면 함수가 중첩함수일 때 상위함수의 유효범위까지 흡수하는 것을 말합니다. 즉, 하위함수가 실행되는 동안 참조하는 상위 함수의 변수 또는 함수의 메모리를 참조하는 것입니다. 앞서 실행 문맥 생성에 대해 설명했듯이 함수가 실행될 때 유효범위를 생성하고 해당 함수를 호출한 부모 함수가 가진 활성화 객체가 리스트에 추가됩니다.
[그림 4] 유효범위 체인 관계형성
쉽게 말해서 위와 같은 코드를 실행할 때 전역 변수 객체, 상 하위 객체 간에 부모/자식 관계가 형성된다고 생각하시면 쉽게 이해 할 수 있습니다. 위의 코드를 실행 문맥 개념으로 좀 더 자세히 보면 다음과 같은 구조를 가집니다.
[그림 5] 유효범위 체인
(앞으로 활성화 객체는 변수 객체와 같기 때문에 변수 객체라고 부르겠습니다) 함수 outerFunction이 실행 되면 outerFunction의 실행 문맥이 생성이 되고 그 과정은 앞선 실행 문맥 생성과정과 동일합니다. outerFunction이 실행이 되면서 내부 함수 innerFunction이 실행되면 innerFunction실행 문맥이 생성이 되는데 유효범위 정보가 생성이 되면서 outerFuction과는 조금 차이가있는 유효범위 체인 리스트가 생깁니다. innerFunction 실행문맥의 유효범위 체인 리스트는 1번지에 상위 함수인 outerFunction의 변수 객체를 참조합니다. 만약 innerFunction내부에 새로운 내부 함수가 생기게 되면 그 내부함수의 유효범위 체인의 1번지는 outerFunction의 변수 객체를, 2번지는 innerFunction의 변수 객체를 참조합니다.
이어서 이 유효범위 체인을 이용한 클로저에 대해 알아 봅니다.
3. 클로저(Closure)
클로저는 JavaScript의 유효범위 체인을 이용하여 이미 생명 주기가 끝난 외부 함수의 변수를 참조하는 방법입니다. 외부 함수가 종료되더라도 내부함수가 실행되는 상태면 내부함수에서 참조하는 외부함수는 닫히지 못하고 내부함수에 의해서 닫히게 되어 클로저라 불리 웁니다. 따라서 클로저란 외부에서 내부 변수에 접근할 수 있도록 하는 함수입니다.
내부 변수는 하나의 클로저에만 종속될 필요는 없으며 외부 함수가 실행 될 때마다 새로운 유효범위 체인과 새로운 내부 변수를 생성합니다. 또, 클로저가 참조하는 내부 변수는 실제 내부 변수의 복사본이 아닌 그 내부 변수를 직접 참조합니다.
function outerFunc(){
var a= 0;
return {
innerFunc1 : function(){
a+=1;
console.log("a :"+a);
},
innerFunc2 : function(){
a+=2;
console.log("a :"+a);
}
};
}
var out = outerFunc();
out.innerFunc1();
out.innerFunc2();
out.innerFunc2();
out.innerFunc1();
//실행결과
/*
a = 1
a = 3
a = 5
a = 6
*/
function outerFunc(){
var a= 0;
return {
innerFunc1 : function(){
a+=1;
console.log("a :"+a);
},
innerFunc2 : function(){
a+=2;
console.log("a :"+a);
}
};
}
var out = outerFunc();
var out2 = outerFunc();
out.innerFunc1();
out.innerFunc2();
out2.innerFunc1();
out2.innerFunc2();
//실행결과
/*
a = 1
a = 3
a = 1
a = 3
*/
[예제 8] 클로저의 상호작용, 서로 다른 객체
위의 코드는 클로저의 예제 코드이며 그 중 좌측 코드는 서로 다른 클로저가 같은 내부 변수를 참조하고 있다는 것을 보여주고 있습니다. 서로 다른 클로저 innerFunc1과 innerFunc2가 내부 변수 a를 참조하고 a의 값을 바꿔주고 있습니다. 실행 결과를 보면 내부 변수 a의 메모리를 같이 공유한다는 것을 알 수 있습니다.
우측 코드는 같은 함수를 쓰지만 서로 다른 객체로 내부 변수를 참조하는 모습입니다. 외부 함수가 여러 번 실행되면서 서로 다른 객체가 생성되고 객체가 생성될 때 마다 서로 다른 내부 변수가 생성되어 보기엔 같은 내부 변수 a로 보이지만 서로 다른 내부 변수를 참조합니다.
3.1 클로저의 사용이유
클로저를 사용하게 되면 전역변수의 오,남용이 없는 깔끔한 스크립트를 작성 할 수 있습니다. 같은 변수를 사용하고자 할 때 전역 변수가 아닌 클로저를 통해 같은 내부 변수를 참조하게 되면 전역변수의 오남용을 줄일 수 있습니다. 또한, 클로저는 JavaScript에 적합한 방식의 스크립트를 구성하고 다양한 JavaScript의 디자인 패턴을 적용할 수 있습니다. 그의 대표적인 예로 모듈 패턴을 말 할 수 있는데 모듈 패턴의 자세한 내용은 [Javascript : 함수(function) 다시 보기]을 참고 하시면 될 것 같습니다. 마지막으로 함수 내부의 함수를 이용해 함수 내부변수 또는 함수에 접근 함으로써 JavaScript에 없는 class의 역할을 대신해 비공개 속성/함수, 공개 속성/함수에 접근을 함으로 class를 구현하는 근거 입니다.
3.2 클로저 사용시 주의할 점
클로저를 사용할 때 주의해야 할 점이 여럿 있습니다. 제가 알려드리고 싶은 주의 점은 다음과 같습니다.
for 문 클로저는 상위 함수의 변수를 참조할 때 자신의 생성될 때가 아닌 내부 변수의 최종 값을 참조합니다.
<body>
<script>
window.onload = function(){
var list = document.getElementsByTagName("button");
for(var i =0, length = list.length; i<length; i++){
list[i].onclick=function(){
console.log(this.innerHTML+"은"+(i+1)+"번째 버튼입니다");
}
}
}
</script>
<button>1번째 버튼</button>
<button>2번째 버튼</button>
<button>3번째 버튼</button>
</body>
//실행결과
/*
1번째 버튼은 4번째 버튼입니다
2번째 버튼은 4번째 버튼입니다
3번째 버튼은 4번째 버튼입니다
*/
[예제 9] for문안의 클로저
위의 코드는 각각의 버튼에 이벤트를 걸어 클릭된 버튼이 몇 번째 버튼인지를 알기 위한 예제 입니다. 하지만, 실행 결과 값은 바라던 결과가 나오지 않습니다. 위의 클로저인 클릭 이벤트가 참조 하는 변수 i의 값이 버튼이 클릭될 때의 값이 아닌 for 구문을 다 돌고 난후 i의 값 4를 참조하기 때문에 모두 4라는 결과가 나옵니다.
<body>
<script>
window.onload = function(){
var list = document.getElementsByTagName("button");
var gate = function(i){
list[i].onclick=function(){
console.log(this.innerHTML+"은"+(i+1)+"번째 버튼입니다");
}
}
for(var i =0, length = list.length; i<length; i++){
gate(i);
}
}
</script>
<button>1번째 버튼</button>
<button>2번째 버튼</button>
<button>3번째 버튼</button>
</body>
//실행결과
/*
1번째 버튼은 1번째 버튼입니다
2번째 버튼은 2번째 버튼입니다
3번째 버튼은 3번째 버튼입니다
*/
[예제 10] 예제9 해결법 : 중첩클로저
위의 예제 코드를 통해 중첩 된 클로저를 사용하는 것 만으로 위와 같은 문제를 피하여 원하는 값이 나옵니다.
성능문제 클로저가 필요하지 않는 부분에서 클로저를 사용하는 것은 처리 속도와 메모리 면에서 좋은 방법이 아닙니다.
function MyObject(inputname) {
this.name = inputname;
this.getName = function() {
return this.name;
};
this.setName = function(rename) {
this.name = rename;
};
}
var obj= new MyObject("서");
console.log(obj.getName());
//실행결과
/*
서
*/
[예제 11] 클로저의 오남용
위의 코드와 같은 함수 내부의 클로저 구현은 함수의 객체가 생성될 때마다 클로저가 생성되는 결과를 가져옵니다. 같은 구동을하는 클로저가 객체마다 생성이 된다면 쓸데없이 메모리를 쓸데없이 차지하게 되는데, 이를 클로저의 오남용이라고 합니다. 클로저의 오남용은 성능 문제 면에서 안 좋은 결과를 가져옵니다.
function MyObject(inputname) {
this.name = inputname;
}
MyObject.prototype.getName = function() {
return this.name;
};
MyObject.prototype.setName = function(rename) {
this.name = rename;
};
var obj= new MyObject("서");
console.log(obj.getName());
//실행결과
/*
서
*/
[예제 12] prototype객체를 이용한 클로저 생성
클로저를 위의 코드와 같이 prototype객체에 생성하게 되면 객체가 아무리 생성되어도 클로저를 한 번만 생성하고 여러 객체에서 쓸 수 있게 되어 메모리의 낭비를 줄입니다.
function f1(){
function f2(){
console.log(arguments[0]);
}
return f2;
}
var exam = f1(1);
exam();
//실행결과
/*
undefined
*/
function f1(){
var a= arguments[0];
function f2(){
console.log(a);
}
return f2;
}
var exam = f1(1);
exam();
//실행결과
/*
1
*/
[예제 13] arguments객체 참조
위의 좌측코드같이 클로저를 통해 arguments객체를 참조하게 되면 undefined라는 실행결과가 나옵니다. 즉, arguments객체는 참조가 불가능하며 굳이 참조하고 싶다면 오른쪽 코드와 같이 새로운 내부 변수에 arguments객체의 값을 넣고 그 변수를 참조 하거나 매개변수를 만들어 매개 변수를 참조하여야 합니다.
Function 생성자
var a= 20;
function function1(){
var a= 10;
var function2 = new Function("","return a;");
return function2;
}
var exam = function1();
exam();
//실행결과
/*
20
*/
[예제 14] Function생성자로 선언된 클로저
위의 코드와 같이 클로저가 Function생성자로 생성된 경우 전역에서 생성된 것으로 인지합니다. 클로저 function2를 통하여 내부 변수 a를 참조하려고 했지만 원했던 결과와 달리 전역 변수 a가 참조 됩니다.
순환참조
function outerFunc(){
var outer_val = {};
function innerFunc(){
console.log(outer_val);
}
outer_val.values = innerFunc;
return innerFunc;
}
[예제 15] 인위적 순환참조
위의 코드는 의도적으로 클로저의 순환참조를 만든 예제 코드입니다. 내부 객체 outerval의 속성 값 values 에 내부 함수 innerFunc를 참조하게 만들고 내부 함수 innerFunc는 내부 객체 outerval을 호출 하고 있습니다. 위와 같은 순환 참조는 서로를 참조 하면서 영원히 끝나지 않는 호출로 인하여 메모리 누수를 야기합니다.
function outerFunc(){
var outer_val = {};
function innerFunc(){
console.log("Hello");
}
outer_val.values = innerFunc;
return innerFunc;
}
[예제 16] 의도치 않은 순환참조
그렇다면 위 코드같이 서로를 참조를 하지 않게 되면 순환참조가 끊어질까요? 아닙니다. JavaScript의 클로저는 특별한 문법을 쓰지 않고도 암묵적으로 생기는 특성을 가지고 있습니다. 이는 클로저를 쉽게 만들도록 해주지만 클로저가 사용되는 곳을 사용자가 식별하기 어렵게 만들기도 합니다. 그렇게 되면 내부 함수의 innerFunc는 암묵적으로 상위 함수의 내부 객체인 outer_val을 참조하게 되고 이로인해 의도치 않게 순환참조가 만들어집니다. 이런 의도치 않은 순환참조는 메모리 누수를 야기합니다.
이 같은 의도치 않은 순환참조는 객체가 제거될 때 명시적으로 null값으로 초기화 해 주거나 try-catch-finally구문으로 해결합니다. 또는 더 글라스 크락포드가 제시한 purge함수를 쓰게 되면 순환참조를 해결할 수 있습니다. 아래는 purge함수 입니다.
function purge(d) {
var a = d.attributes, i, l, n;
if (a) {
for (i = a.length - 1; i >= 0; i -= 1) {
n = a[i].name;
if (typeof d[n] === 'function') {
d[n] = null;
}
}
}
a = d.childNodes;
if (a) {
l = a.length;
for (i = 0; i < l; i += 1) {
purge(d.childNodes[i]);
}
}
}
[더글라스 크락포드의 purge함수]
3.3 캡슐화
캡슐화란 간단하게 말하면 객체의 자료화 행위를 하나로 묶고, 실제 구현 내용을 외부에 감추는 겁니다. 즉, 외부에서 볼 때는 실제 하는 것이 아닌 추상화 되어 보이게 하는 것으로 정보은닉에 쓰입니다. JavaScript는 이와 같은 캡슐화를 클로저를 사용하여 구현합니다.
function Gugudan(dan){
this.maxDan=3;
this.calculate = function(){
for(var i =1; i<=this.maxDan; i++){
console.log(dan+"*"+i+"="+dan*i);
}
}
this.setMaxDan = function(reset){
this.maxDan = reset;
}
}
var dan5 = new Gugudan(5);
dan5.calculate();
dan5.maxDan=2;
dan5.calculate();
//실행결과
/*
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
*/
[예제 17] 캡슐화 전
위의 코드는 JavaScript 캡슐화 하기 전의 코드입니다. 내부 변수를 this객체로 바인딩 하여 선언하게 되면 내부 변수 maxDan에 대하여 외부에서 직접 접근이 가능합니다. 이런식의 소스코드 구현은 사용자가 임의로 바꿔선 안될 값들이 외부에 공개가 되면서 보안문제에 안좋은 결과를 가져옵니다.
function Gugudan(dan){
var maxDan=3;
this.calculate = function(){
for(var i =1; i<=maxDan; i++){
console.log(dan+"*"+i+"="+dan*i);
}
}
this.setMaxDan = function(reset){
maxDan = reset;
}
}
var dan5 = new Gugudan(5);
dan5.calculate();
dan5.maxDan=2;
dan5.calculate();
dan5.setMaxDan(2)
dan5.calculate();
//실행결과
/*
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
5*3=15
5*1=5
5*2=10
*/
[예제 18] 캡슐화 후
하지만 위의 코드와 같이 var키워드를 통하여 내부 변수를 선언하게 되면 내부 변수 maxDan이 외부에서 직접 접근이 되지 않고 오직 클로저를 통해서만 접근이 가능합니다. 즉, 사용자가 임의로 값을 바꿀수 없고 개발자가 만들어놓은 길(클로저)을 통해서만 값을 바꿔 줄수 있습니다. 아쉬운 점은 캡슐화를 하게되면 클로저를 prototype 맴버로 등록하지 못해 공용 메소드로 사용할 수 있는 이점은 사라집니다. 하지만, 별도의 부모 객체를 정의해서 공용 메소드나 상수 들을 위치시키고 이를 상속받는 방식으로 보완할 수 있습니다.
맺음말
다른 프로그래밍 언어와는 조금 다른, 그리고 반드시 알고 지나가야 하는 JavaScript의 유효범위의 개념에대해서 공부하고 정리해보았습니다. 많이 부족한 글이지만 저와같은 초보개발자 분들, 또는 JavaScript를 공부하고 계신 분들에게 조금이나마 도움이 되었으면 하는 바램입니다. 이렇게 글을쓰고 정리하면서 저 또한 많은 공부가 되었던 것 같습니다. 글을 읽으시다가 혹여, 틀리거나 조금 더 정확한 표현이 가능한 부분들이 있다고 생각되시면 바로 저에게 채찍질을 해주셨으면 좋겠습니다. 한 번 틀렸던 부분을 다시알게되면 저에게도 많은 도움이 될 것 같습니다. 읽어 주셔서 감사합니다.